Модуль статистики информационно-аналитической системы “Манускрипт”:
руководство пользователя
Вер. 2.1
В. А. Баранов
Р. М. Гнутиков
Содержание
1. Назначение модуля статистики
2. Подготовка подкорпуса и операции с ним
2.1. Поиск рукописей, текстов, фрагментов
2.3. Использование готового подкорпуса
2.4. Удаление подкорпуса из запросной формы
2.5. Удаление подкорпуса из списка сохраненных подкорпусов
3. Режимы работы и примеры запросов
3.1. Количественная оценка распределения лингвистических единиц в рукописи(ях)
3.1.1. Распределение единиц в одной рукописи
3.1.2. Распределение единиц в нескольких рукописях
3.1.3. Распределение единиц во фрагментах текстов
3.1.5. Параметры запросной формы, использующиеся в режиме поиска распределения единиц
3.2. Сопоставление количества лингвистических единиц в подкорпусах (фрагментах, текстах, рукописях)
3.2.2. Количественная оценка лингвистических единиц в текстах или рукописях
3.2.3. Вывод суммированного результата
3.2.4. Использование значения текст в параметре Тип единицы
3.2.5. Количественная оценка лингвистических единиц во фрагментах
3.2.6. Параметры запросной формы, использующиеся в режиме сопоставления выборок
3.3. Статистическая оценка лингвистических единиц в подкорпусе(ах)
4.1.1. Единица анализа. Параметр “Тип единицы”
4.1.2. Единица подкорпуса. Параметр “Тип шага”
4.1.3. Группировка единиц подкорпуса. Параметры “Тип шага / Свойство для группировки”
4.1.4. Длина шага. Параметр “Шаг”
4.1.5. Способ демонстрации. Параметр “Объединить”
4.1.6. Алфавит вывода единиц. Параметр “Алфавит”
4.2. Количественные и статистические параметры
4.3. Параметры лингвистической единицы
4.3.1. Маска лингвистической единицы. Параметр “Единица”
4.3.2. Виртуальная клавиатура. Параметр “Набор символов”
4.3.3. Количество лингвистических единиц и расстояние между ними. Параметр “Расстояние”
4.3.4. Объединение результатов выборки. Параметр “Объединить”
4.3.5. Применение маски к типу единицы. Параметр “Интерпретация маски”
4.3.6. Соответствие маски и текстового прецедента. Параметр “Точность”
4.3.7. Учет грамматических значений. Параметр “Грамматические признаки”
4.3.8. Использование лемм со снятой омонимией. Параметр “Снимать омонимию”
4.4. Дополнительные возможности
4.4.2. Поиск в выборке. Поле “Искать”
4.4.3. Уточнение выборки. Поле “Фильтр”
4.5. Комбинирование параметров
Модуль предназначен для получения сведений о количественных и статистических характеристиках различного типа единиц в подкорпусах исторического корпуса “Манускрипт”, сформированных из рукописей, текстов или фрагментов.
Сведения о количестве или статистических значениях единиц могут быть получены как для одного подкорпуса, так и для нескольких. Подкорпус может включать как одну рукопись (текст, фрагмент), так и две и более.
Запросная форма позволяет сформировать подкорпус, выбрать тип анализируемой единицы (символ, текстовую форму, лемму, текст), указать тип шага (окна, части, фрагмента), в пределах которого единицы анализируются, его длину, выбрать количественный или статистический параметр оценки, ввести маску единицы, выбрать табличное или графическое представление результата и др.
Адрес модуля: http://manuscripts.ru/mns/!cred2.stat.
Рис. 1. Запросная форма модуля
Поиск рукописей, текстов и их фрагментов осуществляется на основе их мета- и аналитических описаний.
Для поиска рукописей, текстов или фрагментов используется переход по гиперссылке «Создать выборку» или поисковая строка главной страницы модуля.
Первый вариант позволяет сохранить созданный подкорпус и анализировать его неоднократно, второй – использовать подкорпус только в текущем сеансе, после закрытия модуля подкорпус удаляется.
Поисковая строка главной страницы модуля позволяет найти рукопись (рукописи), текст (тексты) или фрагмент (фрагменты), отметить их с помощью чекбоксов, указав те, в которых необходимо осуществить анализ единиц.
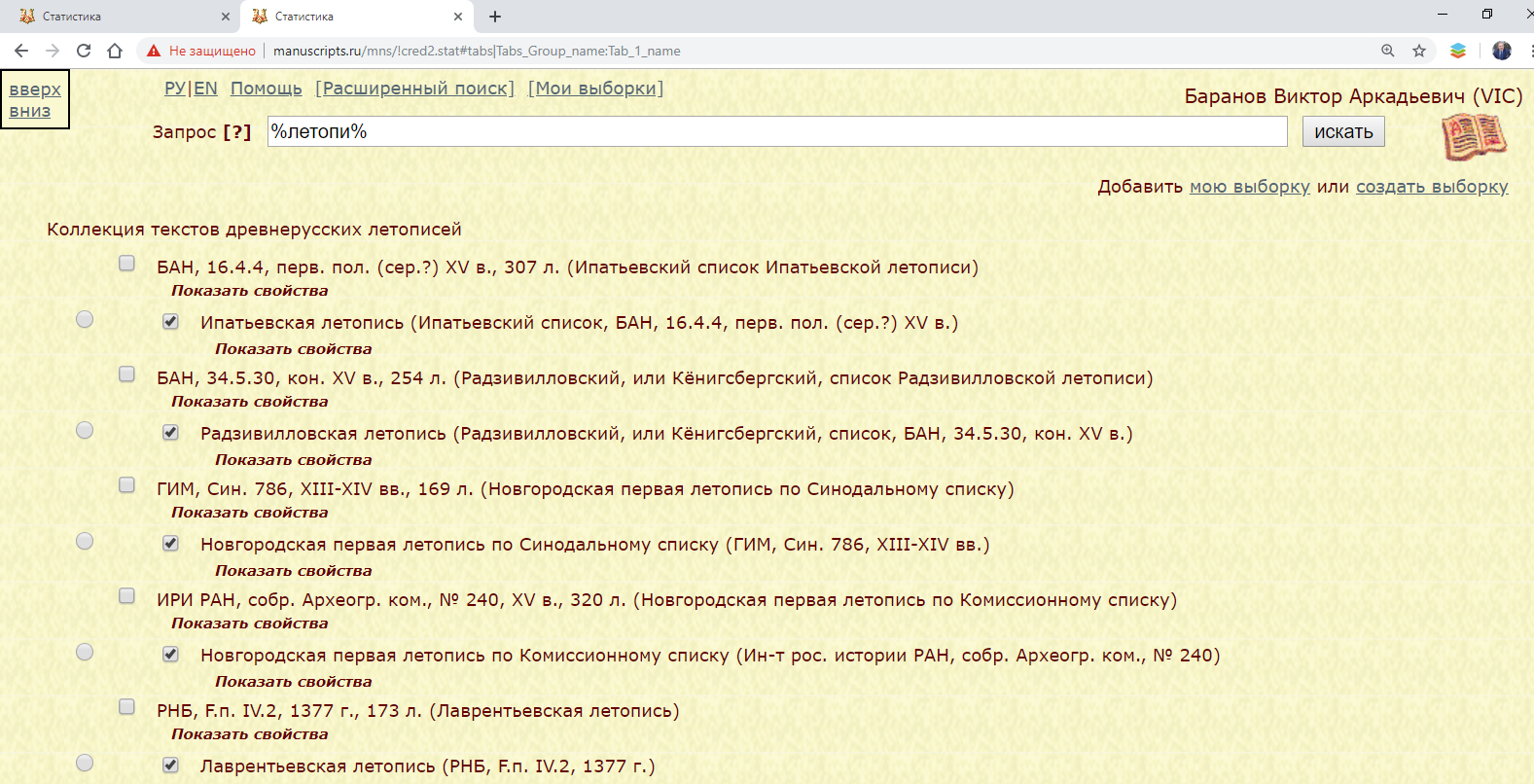
В строке “Запрос” введите слово, часть слова для поиска рукописей, текстов или фрагментов, например: летопи или %летопи%.
В чекбоксах рукописей, текстов или фрагментов отметьте необходимые, например: Ипатьевская летопись, Радзивилловская летопись и др.
Рис. 2.1. Поиск и выбор текстов
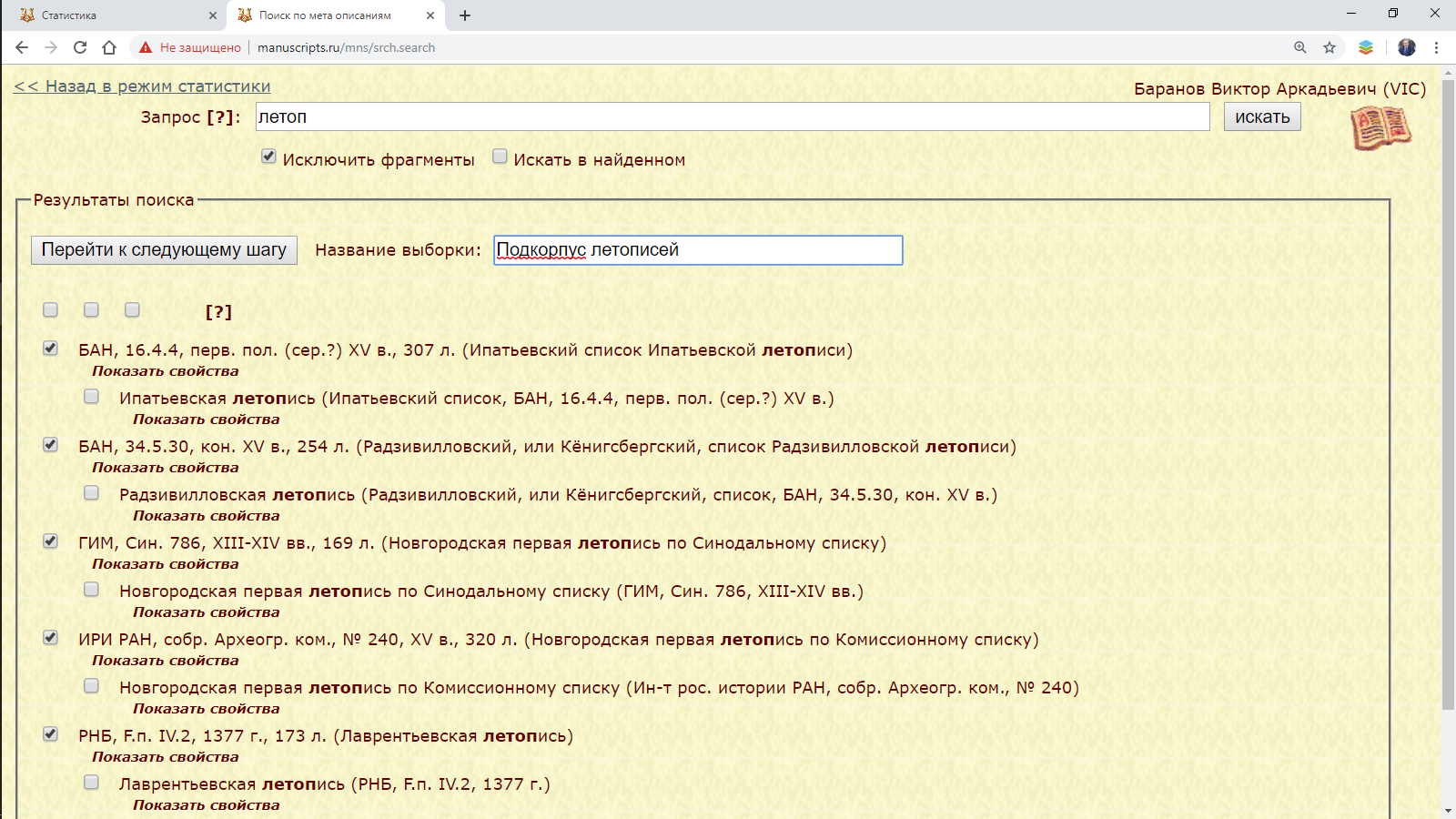
Использование гиперссылки «Создать выборку» позволяет перейти к странице поиска, позволяющей сохранить выборку, с помощью поисковой строки найти рукописи (тексты, фрагменты), отметить необходимые, ввести название выборки и сохранить ее, нажав «Перейти к следующему шагу».
Рис. 2.2. Поиск и выбор рукописей и сохранение подкорпуса
Примечания.
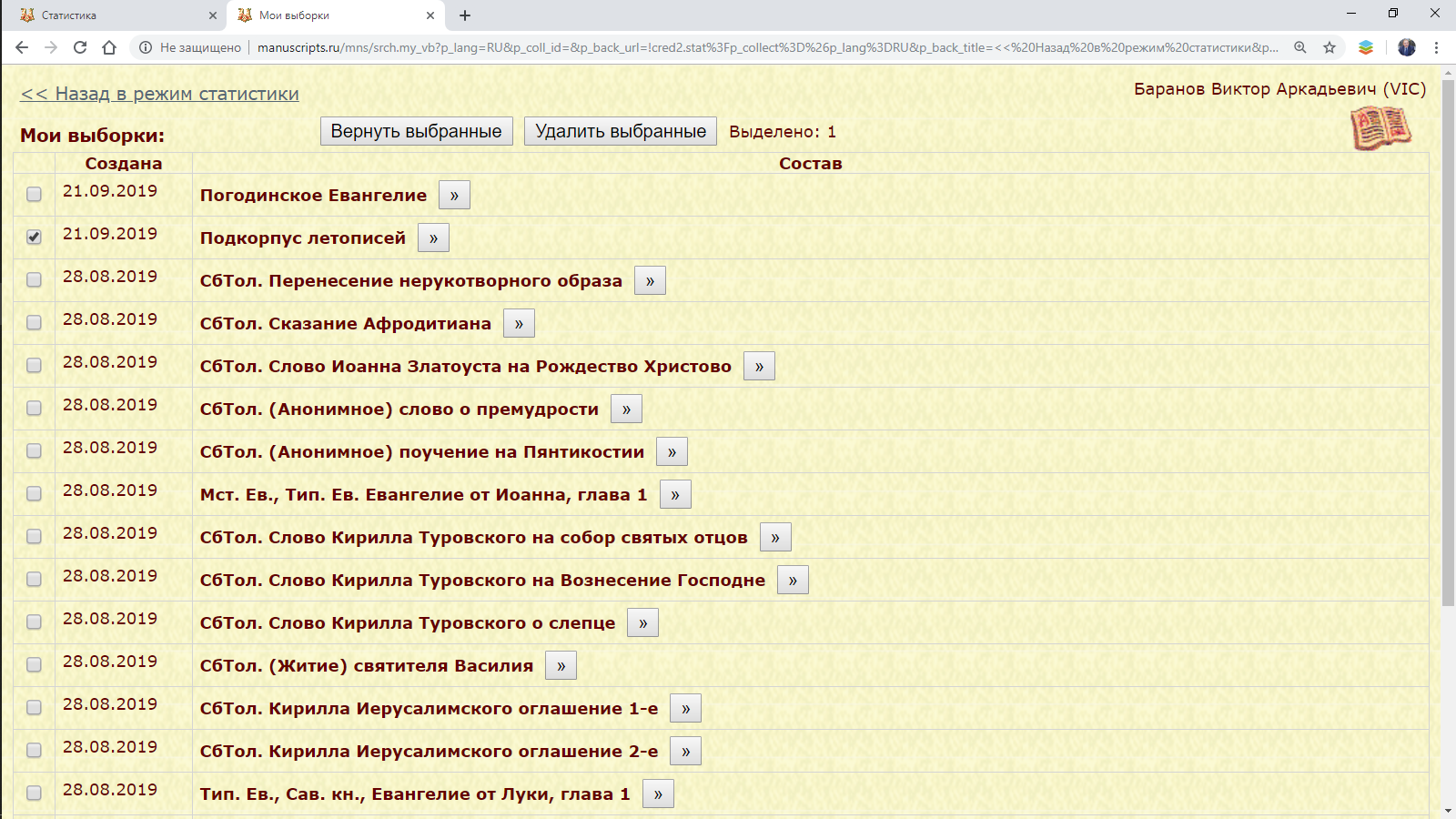
Для использования сохраненных подкорпусов зайдите по гиперссылке “Мои выборки”, выберите нужные и вернитесь в модуль с помощью “Вернуть выбранные”.
Рис. 2.3. Выбор сохраненных подкорпусов
Для удаления нескольких загруженных подкорпусов из запросной формы выберите “(убрать)”.
Для удаления из запросной формы одного подкорпуса загрузите второй или несколько других и удалите ненужный.
Для удаления сохраненных подкорпусов войдите в “Мои выборки”, выберите ненужные и нажмите “Удалить выбранные”.
Предусмотрено несколько режимов работы модуля:
Для нахождения распределения символа, словоформы, леммы на страницах (листах) рукописи:
Примечания.
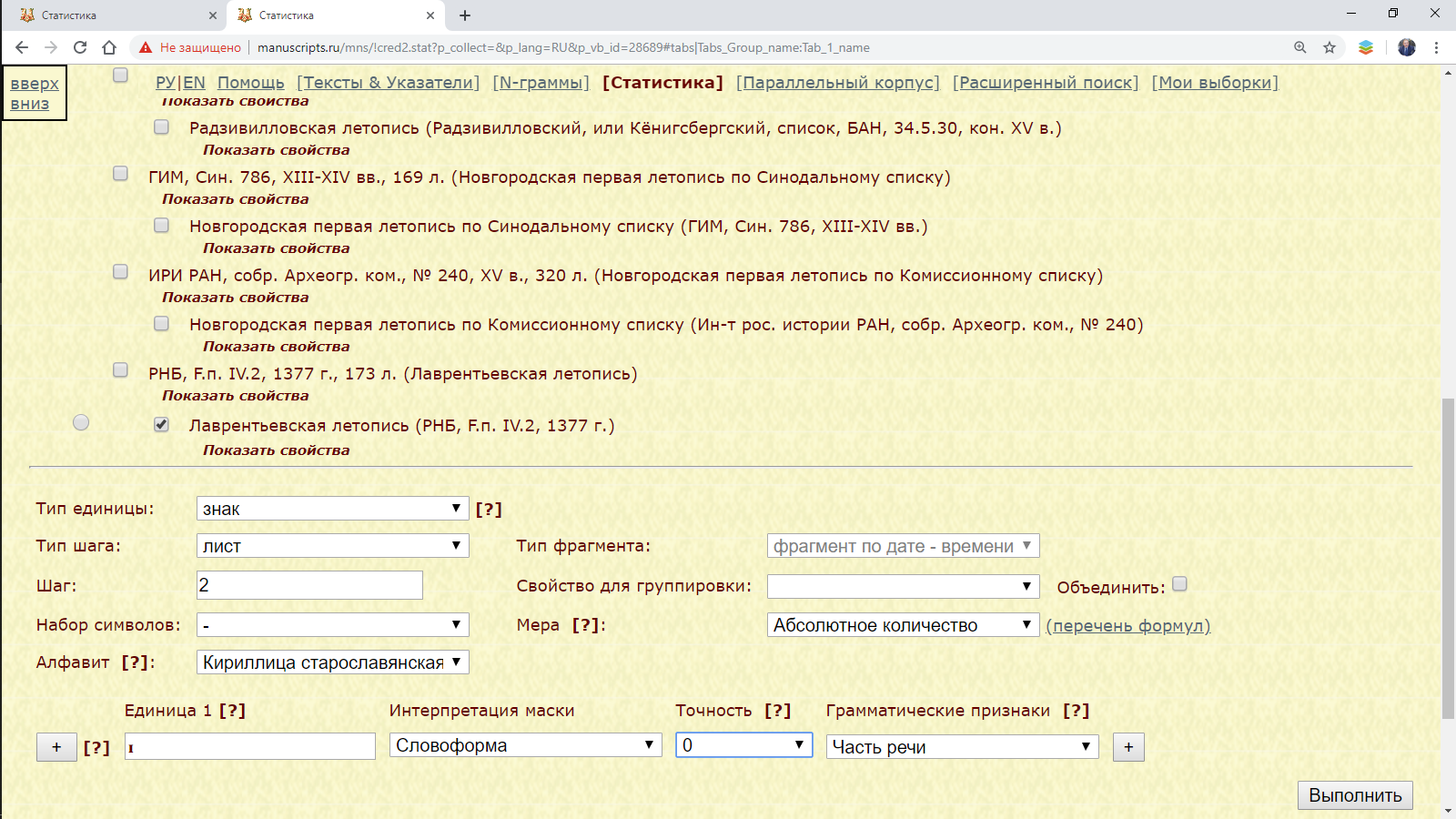
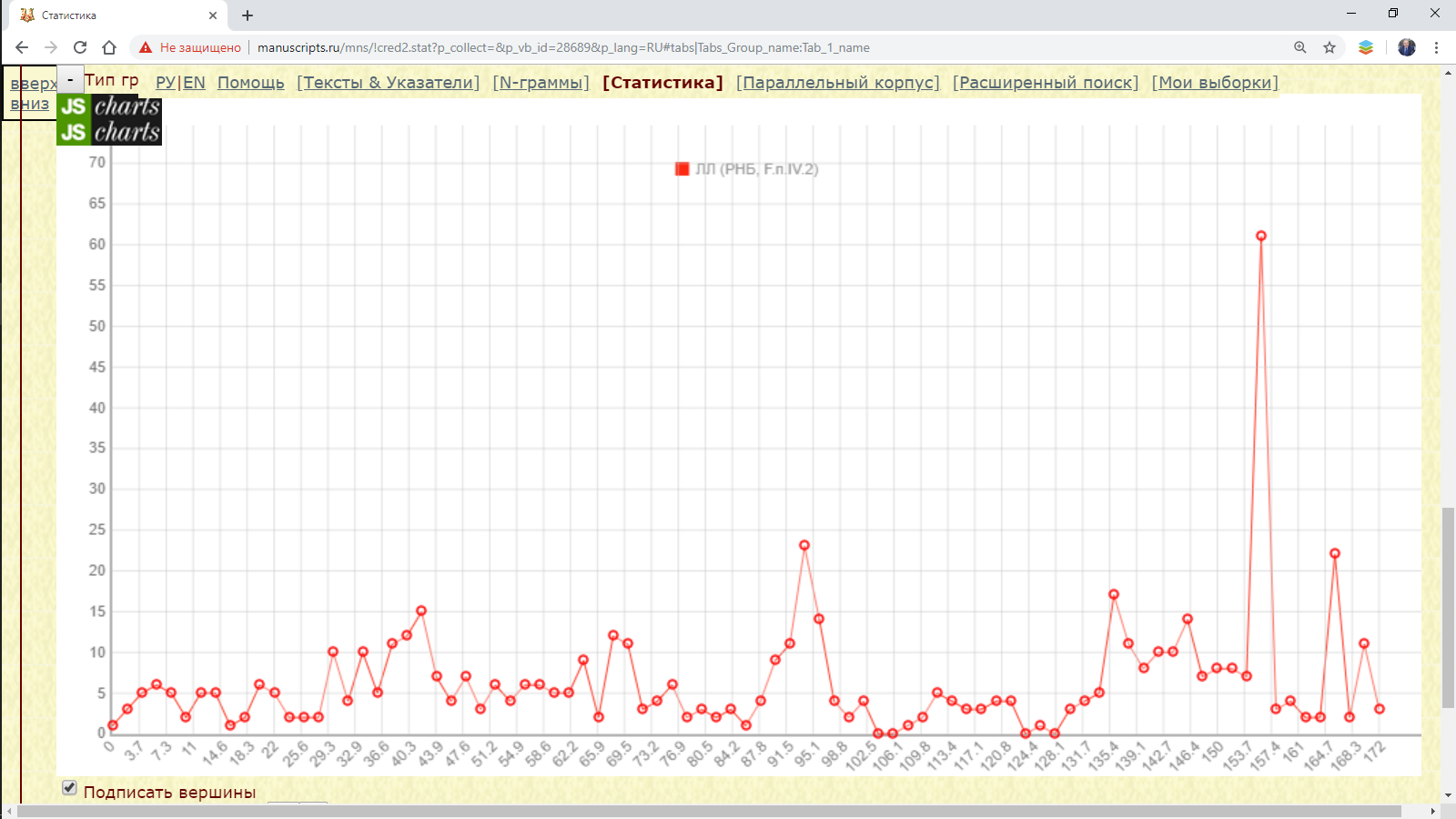
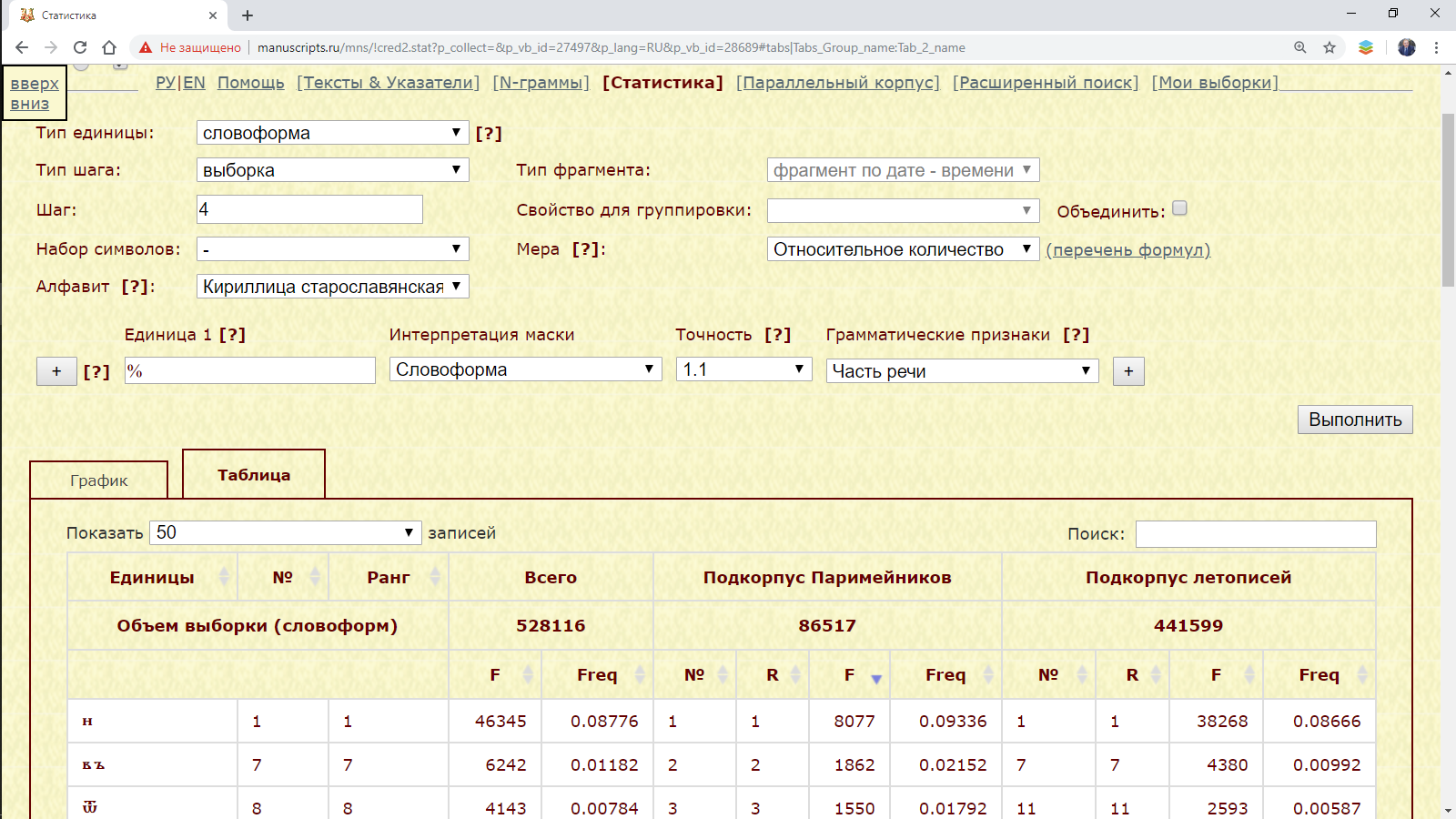
Пример 3.1.1. Запрос на основе одной рукописи: найти распределение десятеричного I на листах Лаврентьевской летописи.
Рис. 3.1.1.а. Запрос для поиска распределения десятеричного I в Лаврентьевской летописи
Результат:
Рис. 3.1.1.б. Распределение десятеричного I в Лаврентьевской летописи (абсолютное количество)
Отметьте несколько текстов выборки, установите значения параметров запросной формы (с помощью радиальной кнопки укажите текст основного списка).
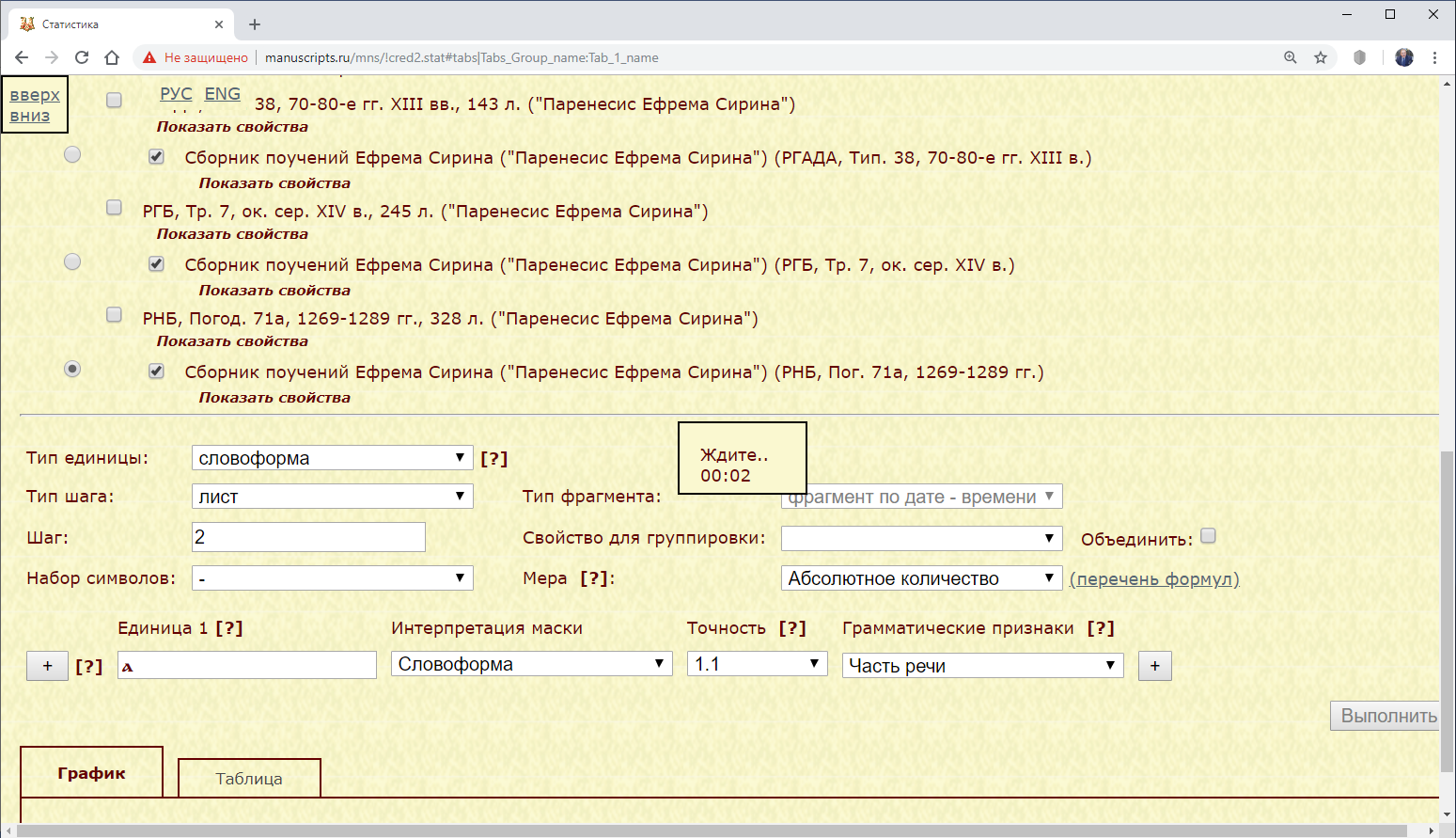
Пример 3.1.2. Запрос на основе нескольких рукописей: найти распределение союза “а” на листах трех списков поучений Ефрема Сирина.
Рис. 3.1.2.а. Запрос для поиска распределения союза “а” в трех списках поучений Ефрема Сирина
В связи с тем, что рукописи имеют различное количество листов, которые являются типом шага, графики имеют разную длину.
Результат:
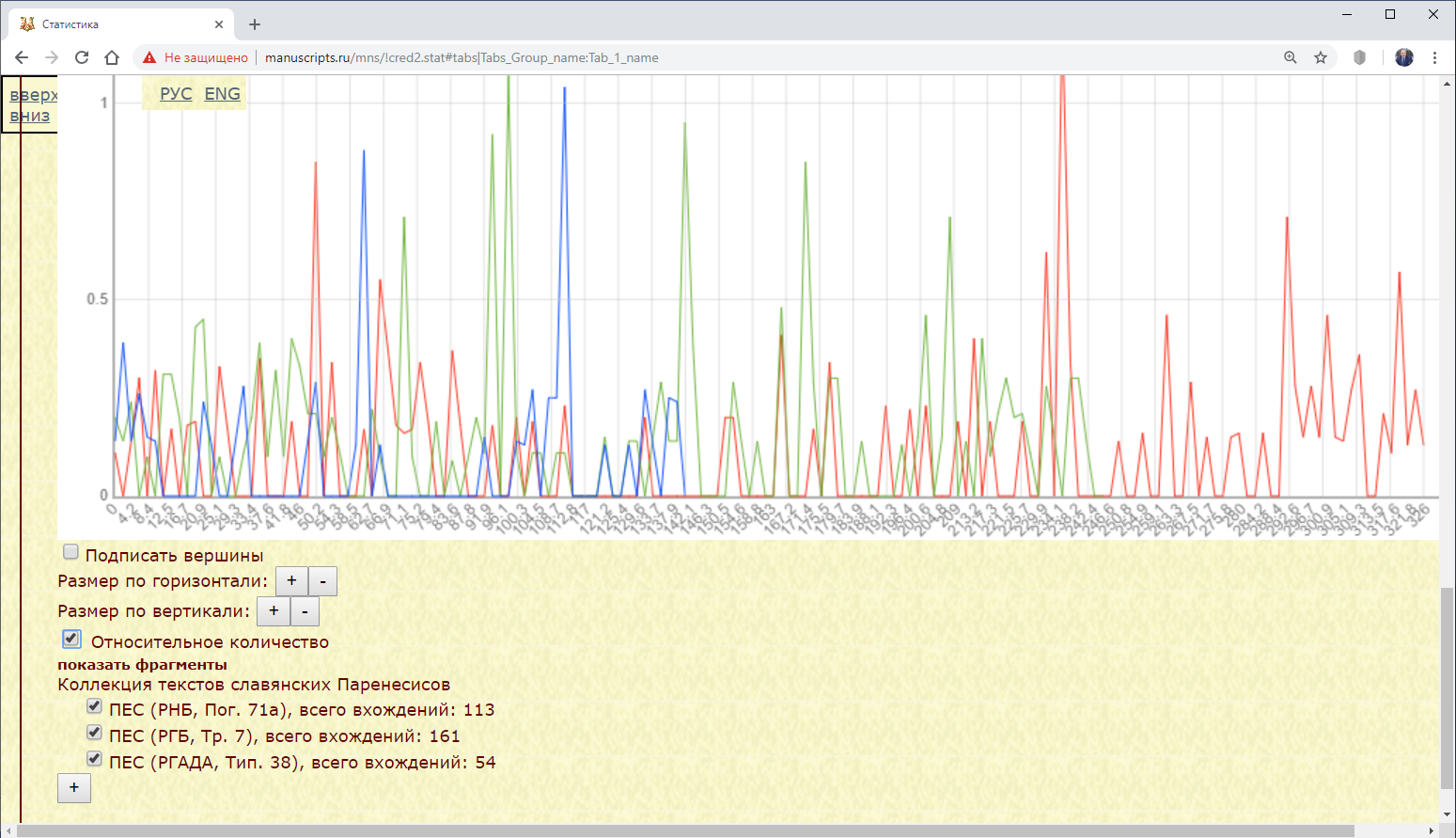
Рис. 3.1.2.б. Распределение союза “а” в трех списках поучений Ефрема Сирина
Выбрав в параметре Тип шага значения страница, знак или словоформа, можно получить сведения о распределении единиц в пределах указанных в параметре Шаг диапазонов страниц, знаков, словоформ.
Если рукописи (тексты) подкорпуса имеют однотипную разметку, то можно получить сведения о единицах на основе выровненных относительно друг друга фрагментов.
Для этого в параметре Тип шага необходимо выбрать значение «фрагмент», а в параметре тип фрагмента – значение фрагмента. Например, для летописей – Погодная запись, для Евангелий – Стих Библии, для миней – функционально-структурный раздел. С помощью радиальной кнопки необходимо указать текст, относительного фрагментов которого будут выравниваться соответствующие фрагменты других текстов.
Для нахождения распределения символа, словоформы, леммы в текстах с учетом фрагментов:
Примечания.
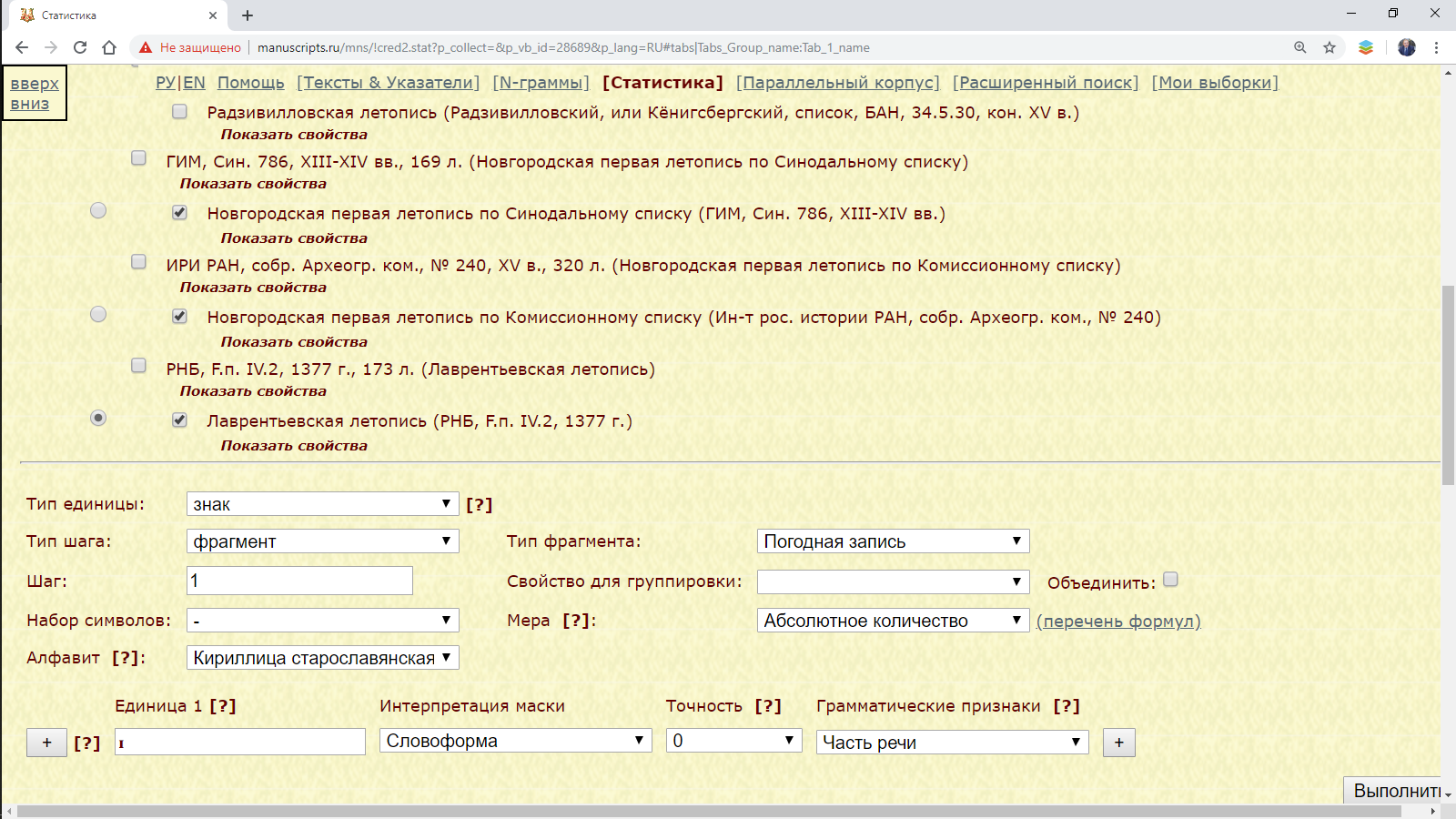
Пример 3.1.3.1: найти распределение I десятеричного в нескольких летописях.
Рис. 3.1.3.1.а. Запрос для поиска распределения I десятеричного в нескольких летописях
Результат:
Рис. 3.1.3.1.б. Распределение I десятеричного в нескольких летописях (абсолютное количество)
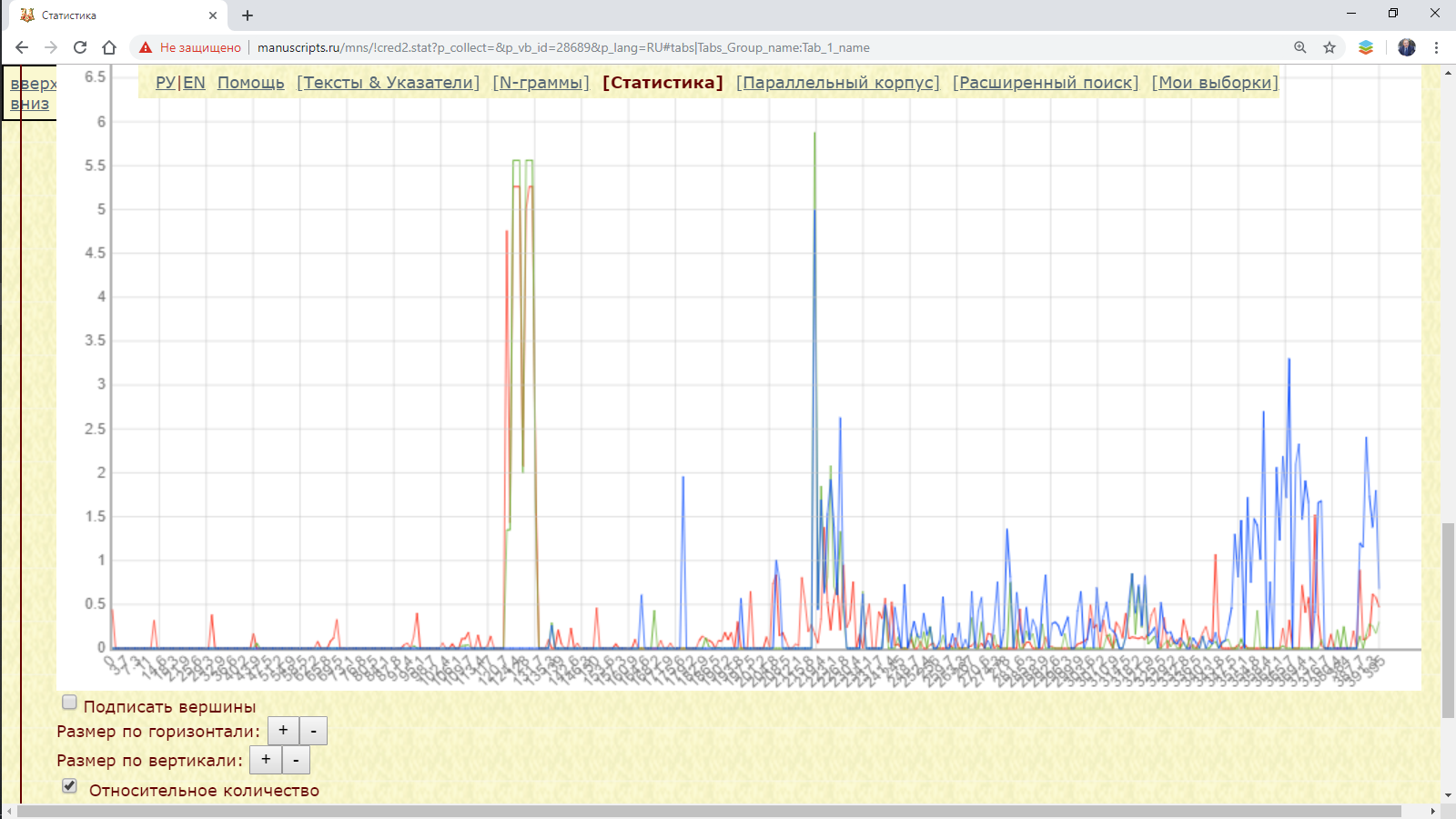
Примечание. При отсутствии фрагмента в сопоставляемом тексте график спускается под нулевое значение.
Для сравнения фрагментов, имеющих различный объем, с помощью чекбокса Относительное количество под графиком предусмотрен перевод абсолютных величин в относительные – количество анализируемых единиц в шаге (окне) делится на общее количество единиц в этом шаге (окне).
Примечание. При выборе перед выполнением запроса значения “Относительное количество” в параметре Мера результатом является количество искомых единиц в шаге (окне) относительно общего количества единиц во всем подкорпусе.
Рис. 3.1.3.1.в. Распределение I десятеричного в нескольких летописях (относительное количество)
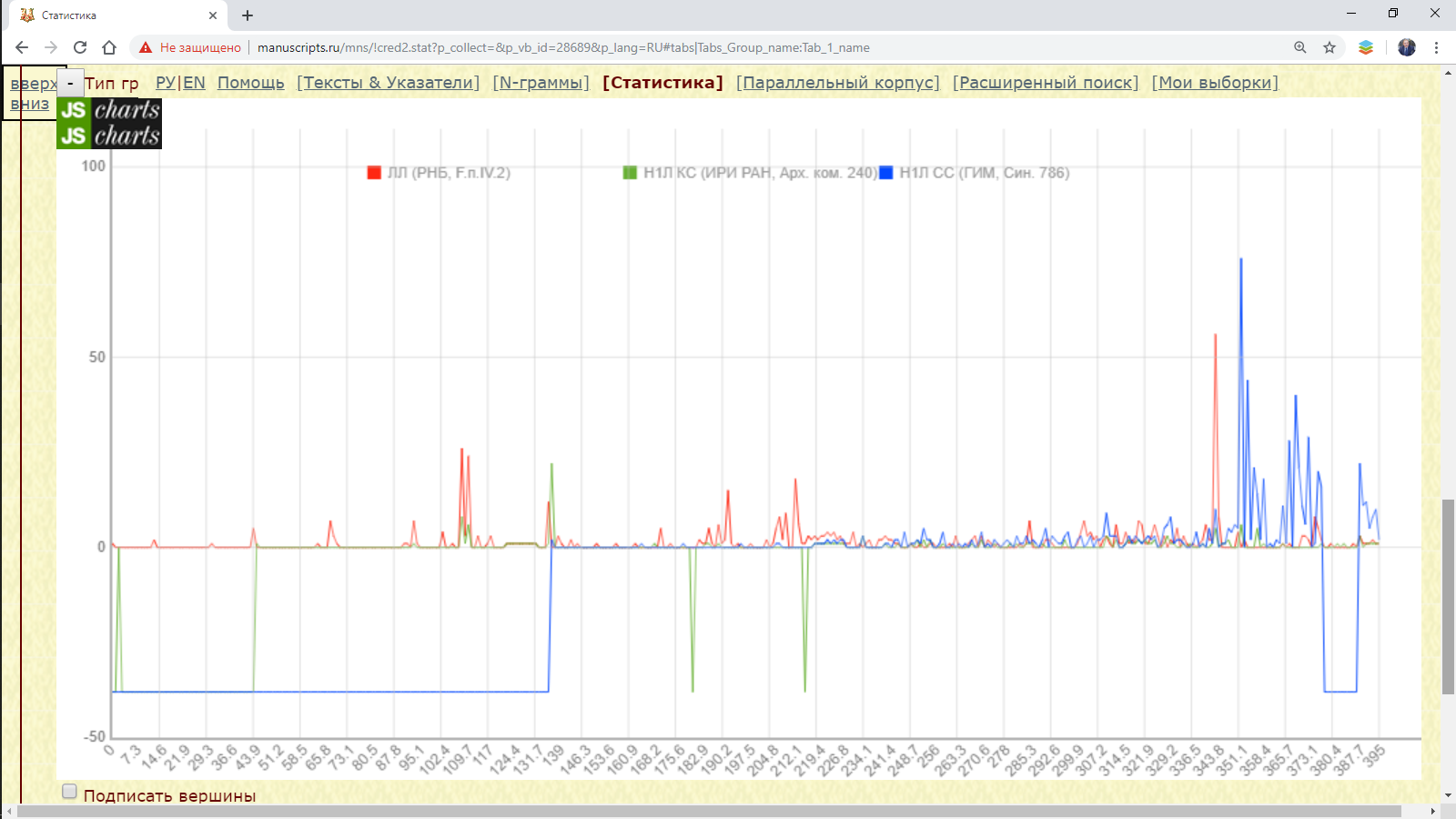
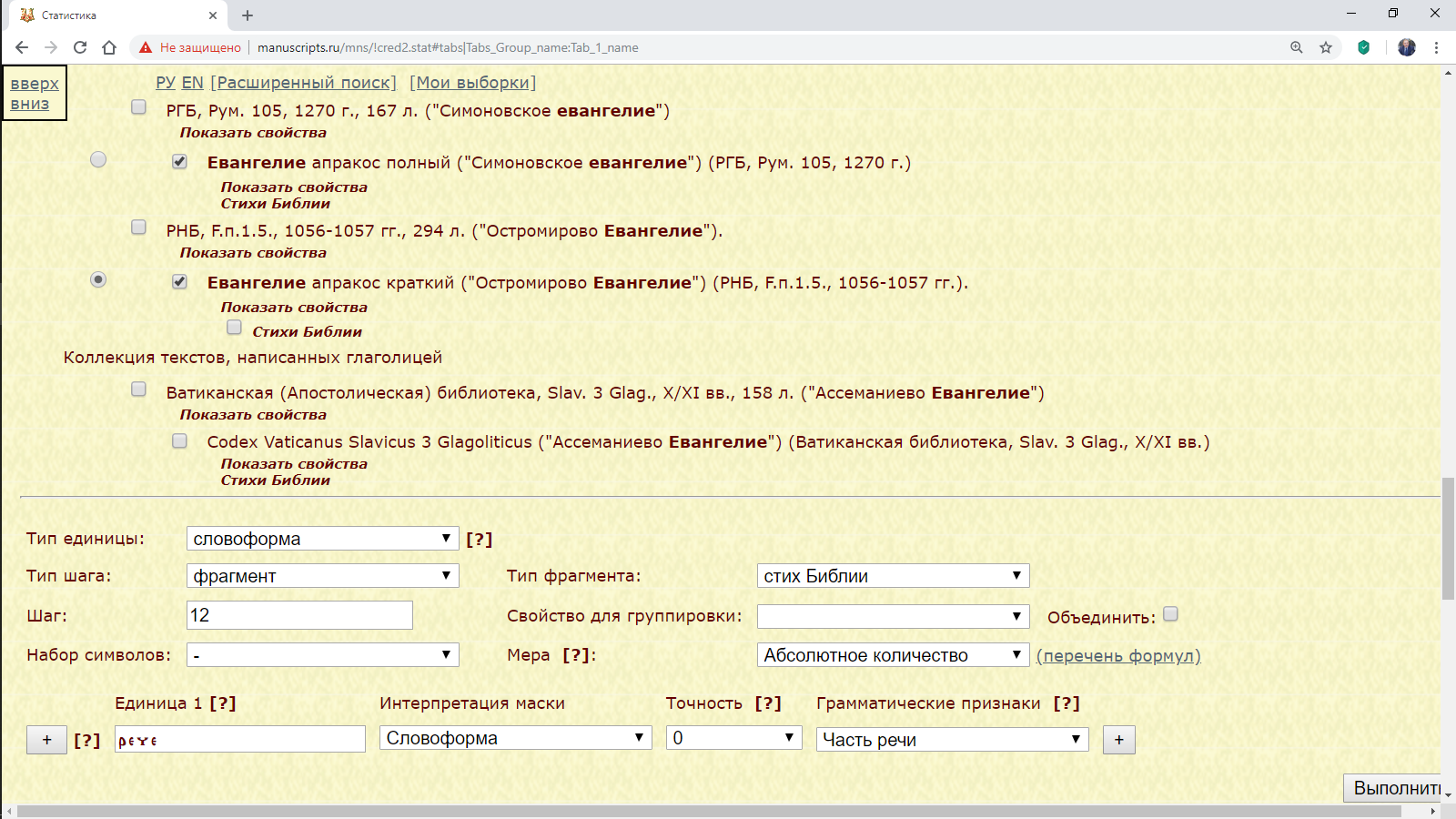
Пример 3.1.3.2: найти распределение формы рече во фрагментах нескольких списков Евангелий.
Рис. 3.1.3.2.а. Запрос для поиска распределения формы рече в нескольких списках Евангелий
Результат:
Рис. 3.1.3.2.б. Распределение формы рече в нескольких списках Евангелий
С помощью параметра Подписать вершины можно получить сведения о шаге (окне) и его единицах. Подписи вершин содержат следующие сведения:
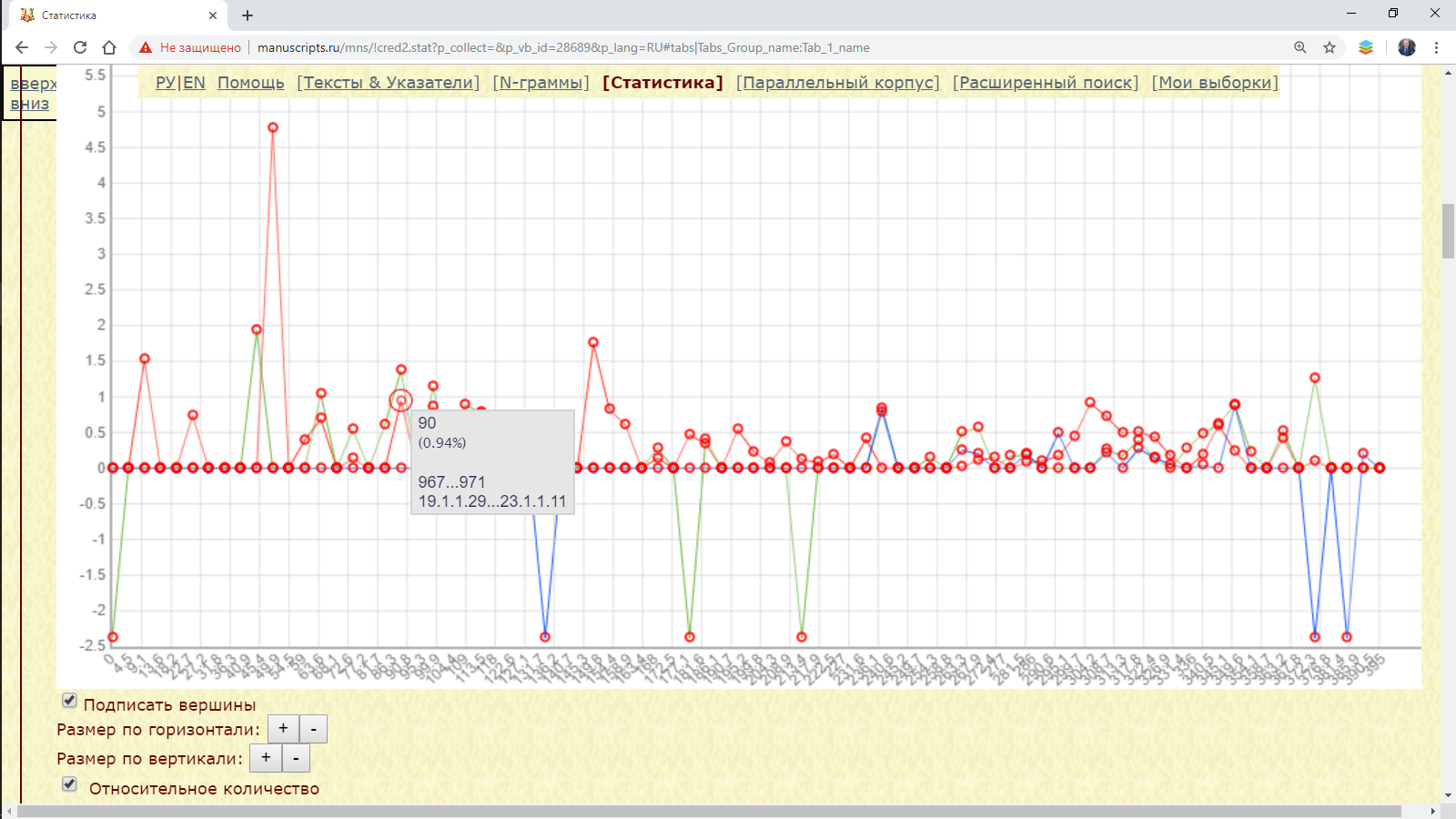
Пример 3.1.4: распределение форм с начальным град в нескольких летописях, визуализация сведений о шаге и переход к контекстам.
Рис. 3.1.4.а. Распределение форм с начальным град в нескольких летописях, визуализация сведений о шаге и переход к контекстам
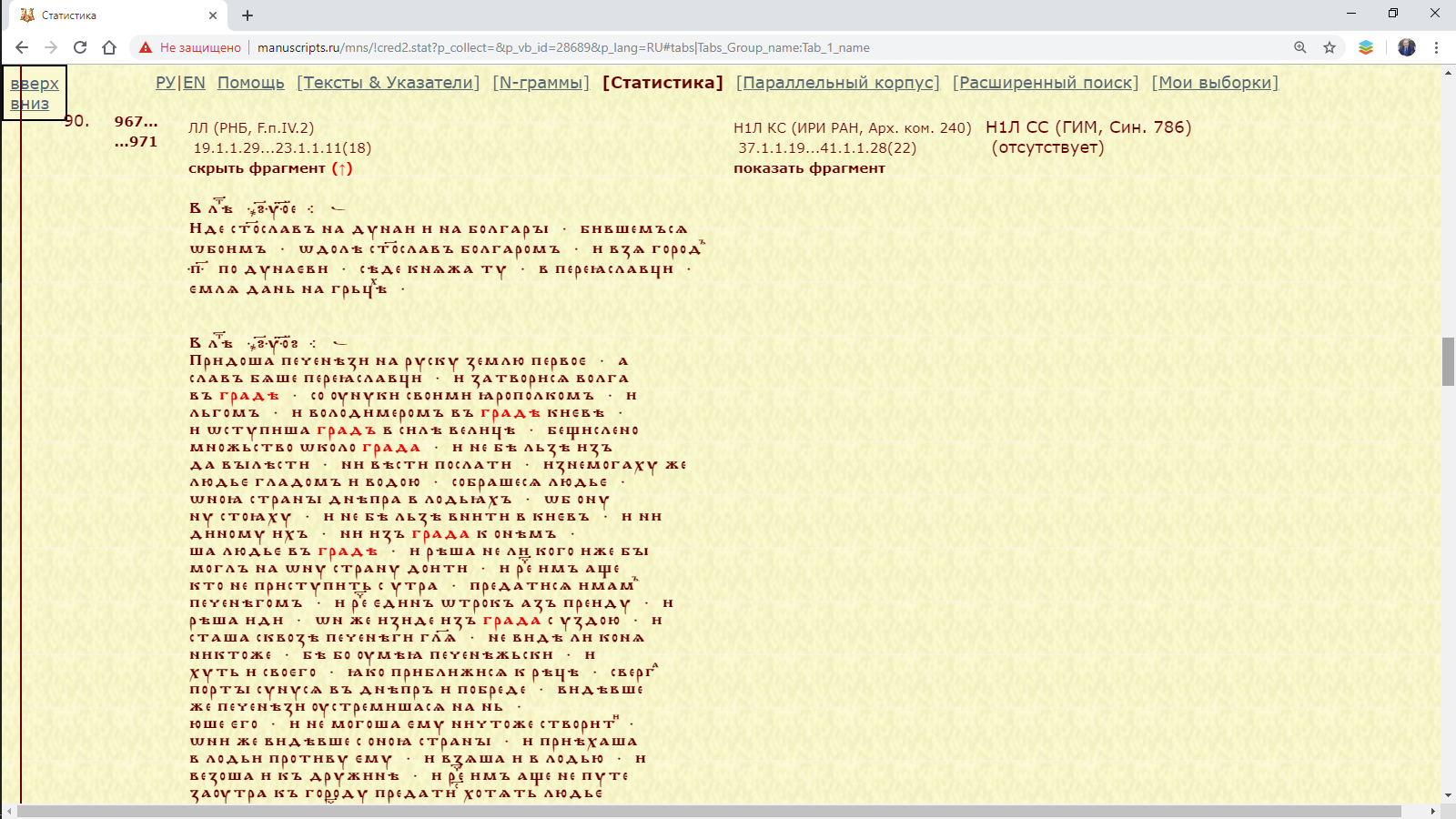
При нажатии выделенной вершины осуществляется контекстный поиск фрагментов этого окна (в контексте анализируемые единицы выделены красным цветом, открытие второго и следующего фрагментов осуществляется с помощью гиперссылки в конце фрагмента):
Рис. 3.1.4.б. Контексты, содержащие формы с начальным град в погодных записях за 967-971 гг. (лл. 19-23) Лаврентьевской летописи
Параметр Тип единицы позволяет установить, какая единица будет анализироваться – словоформа, символ или лемма.
Параметр Тип шага устанавливает в пределах каких фрагментов будут подсчитываться анализируемые единицы – страниц, листов, словоформ, знаков, фрагментов. Если рукопись включает несколько текстов (произведений), то подсчет может быть осуществлен в каждом из них или в нескольких.
Числовое значение параметра Шаг указывает размер шага (окна) подсчета в выбранных единицах шага.
Поле параметра Единица предназначено для ввода маски анализируемой единицы. Для подсчета всех единиц окна используется знак процента – %.
Возможность использовать все символы при указании маски обеспечивается параметром Набор символов. Выбор необходимого типа символов позволяет ввести их в поле Единица. Если не выбран ни один из диапазонов предлагается использовать стандартные символы старославянского алфавита.
Параметр Тип фрагмента используется при работе с текстами, которые имеют аналитическую разметку. Параметр активируется при выборе единицы «фрагмент» в параметре Тип шага.
??Параметр Свойство для группировки позволяет выбрать значение фрагмента, на основе которого фрагменты будут расположены в выдаче.
Изменение значения параметра Интерпретация маски позволяет указать, какие единицы используются при поиске – словоформы или леммы. Значения Регулярное выражение позволяет использовать в поле Единица символы и синтаксис регулярных выражений.
Параметр Точность позволяет указать для словоформ степень точности совпадения маски и текстовой формы. При значении 0 поиск осуществляется с учетом всех особенностей транскрипции словоформы, при других значениях – нивелируются некоторые особенности графической формы. Наибольшее устранение вариантов происходит при значениях 1 и 1.1. Максимальная унификация может быть достигнута использованием в поле Единица маски на основе букв современного кирилловского алфавита и степени точности 1 или 1.1.
С помощью параметра Грамматические признаки можно наложить фильтр на словоформы и леммы, указав значения, которым будут удовлетворять искомые лингвистические единицы. Следует учесть, что параметр работает только в случае автоматической морфологической разметки текста, а в выборку попадают только текстовые формы, имеющие морфологическую разметку и приведенные к лемме.
Поиск нескольких единиц. С помощью знака + слева от поля маски единицы можно открыть поля для ввода второй, третьей и т. д. маски единиц. По умолчанию результатом использования двух и более масок является нахождение таких окон, в которых встречаются все указанные единицы.
??Параметр Расстояние дает возможность указать, на каком расстоянии друг от друга находятся искомые единицы. Значение 0 указывает на контакт компонентов.
С помощью режима Создать выборку подготовьте несколько выборок. В выборку можно включать как одну рукопись (текст, фрагмент), так и несколько.
С помощью гиперссылки Добавить мою выборку загрузите две или несколько выборок.
Для нахождения количественных данных о символах, словоформах, леммах в текстах:
Примечания.
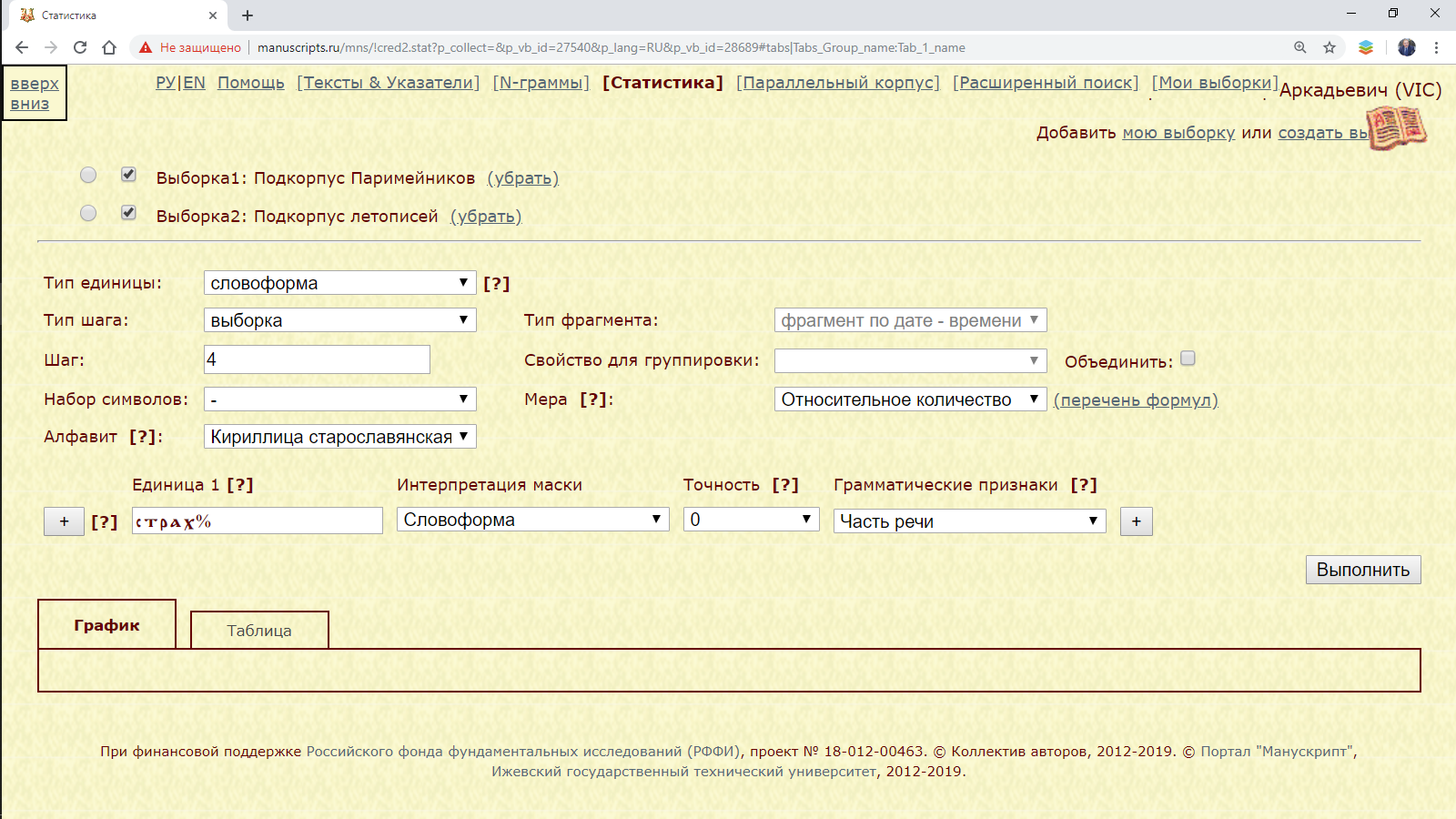
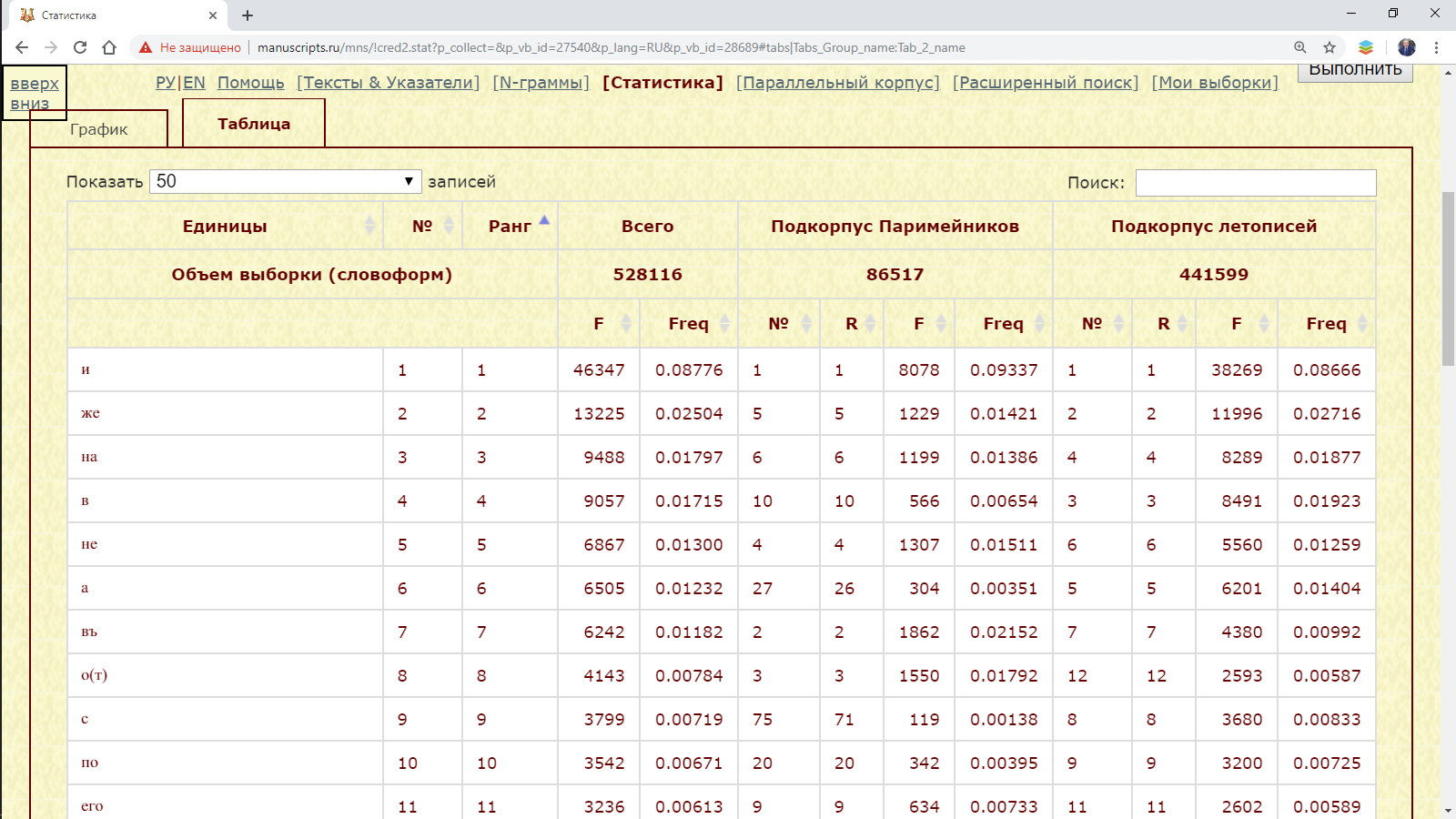
Пример 3.2.2.1. Сопоставить количество слов с начальным страх в подкорпусе Паримейников и подкорпусе летописей.
Рис. 3.2.2.1.а. Запрос для нахождения количества слов с начальным страх в подкорпусах Паримейников и летописей
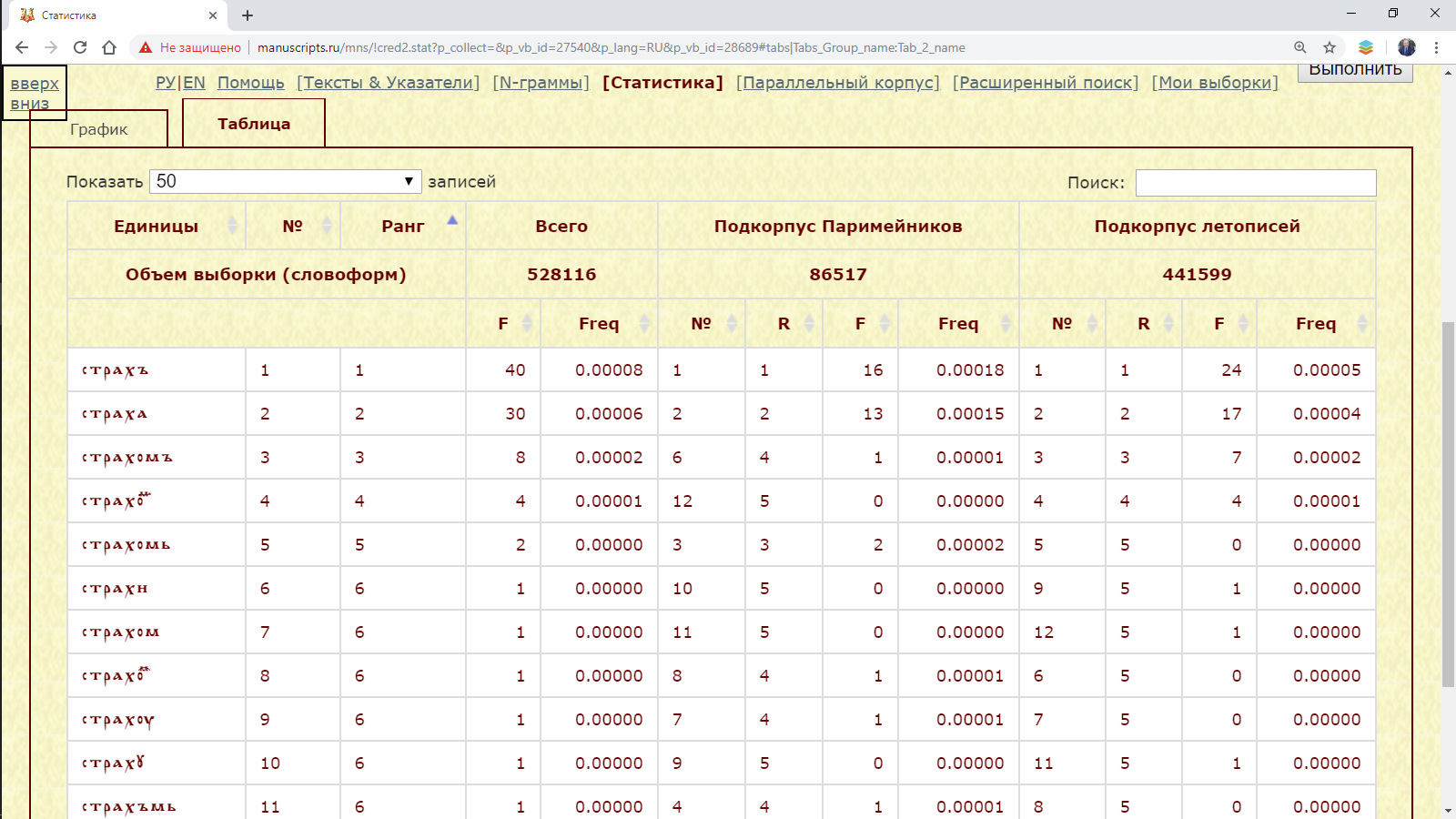
Результат. Результатом выполнения запроса является таблица, которая содержит перечень лингвистических единиц, отсортированных по суммированному их количеству в сравниваемых подкорпусах, а также количество, ранги единиц и их номера по порядку в каждом из подкорпусов.
Рис. 3.2.2.1.б. Перечень текстовых форм с начальным страх в подкорпусах Паримейников и летописей
Перечень единиц можно отсортировать по значениям любого из параметров таблицы, используя соответствующие маркеры сортировки. Вторичную сортировку лингвистических единиц можно сделать, используя маркер сортировки при зажатой клавише Shift.
В большом списке найти единицы можно с помощью поля Поиск.
Использование в поле Единица символа % (любая единица) позволяет сравнить полные перечни текстовых форм или лемм подкорпусов.
Пример 3.2.2.2. Найти наиболее частотные текстовые формы двух подкорпусов.
Рис. 3.2.2.2. Наиболее частотные формы в подкорпусах Паримейников и летописей
Поле для поиска в правом верхнем углу таблицы позволяет найти запись с необходимой единицей.
Использование значения Кириллица современная параметра Алфавит позволяет нивелировать графические различия текстовых форм.
Пример 3.2.2.3. Найти наиболее частотные словоформы двух корпусов и вывести их перечень в транслитерированной форме.
Результат:
Рис. 3.2.2.3. Перечень наиболее частотных слов и словоформ в транслитерированном виде
Для суммирования всех форм, попавших в выборку, необходимо воспользоваться параметром Объединить.
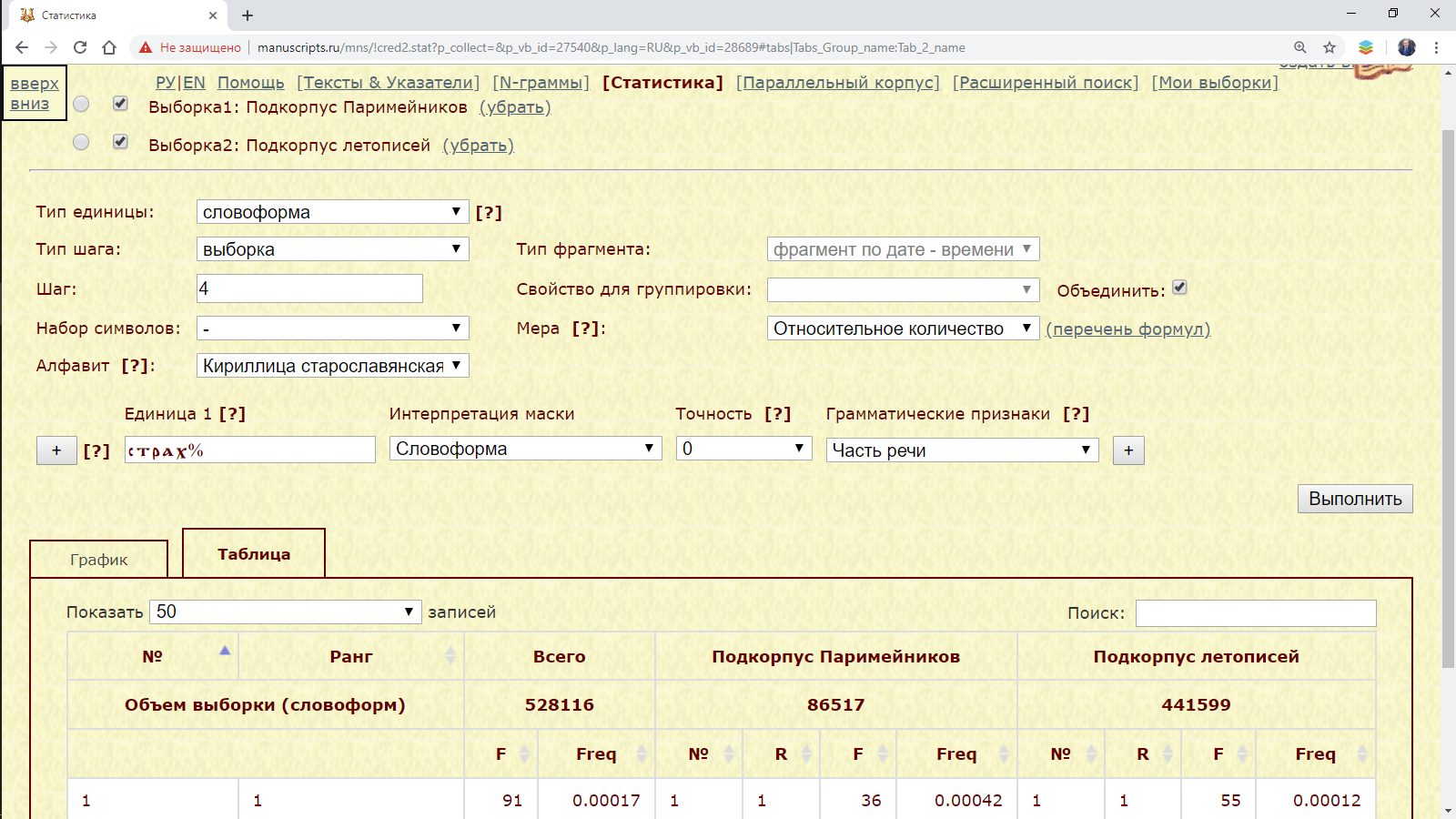
Пример 3.2.3.1. Найти среднее относительное количество слов с начальным страх в подкорпусе Паримейников и подкорпусе летописей.
Результат:
Рис. 3.2.3.1. Среднее относительное количество слов с начальным страх в подкорпусах Паримейников и летописей
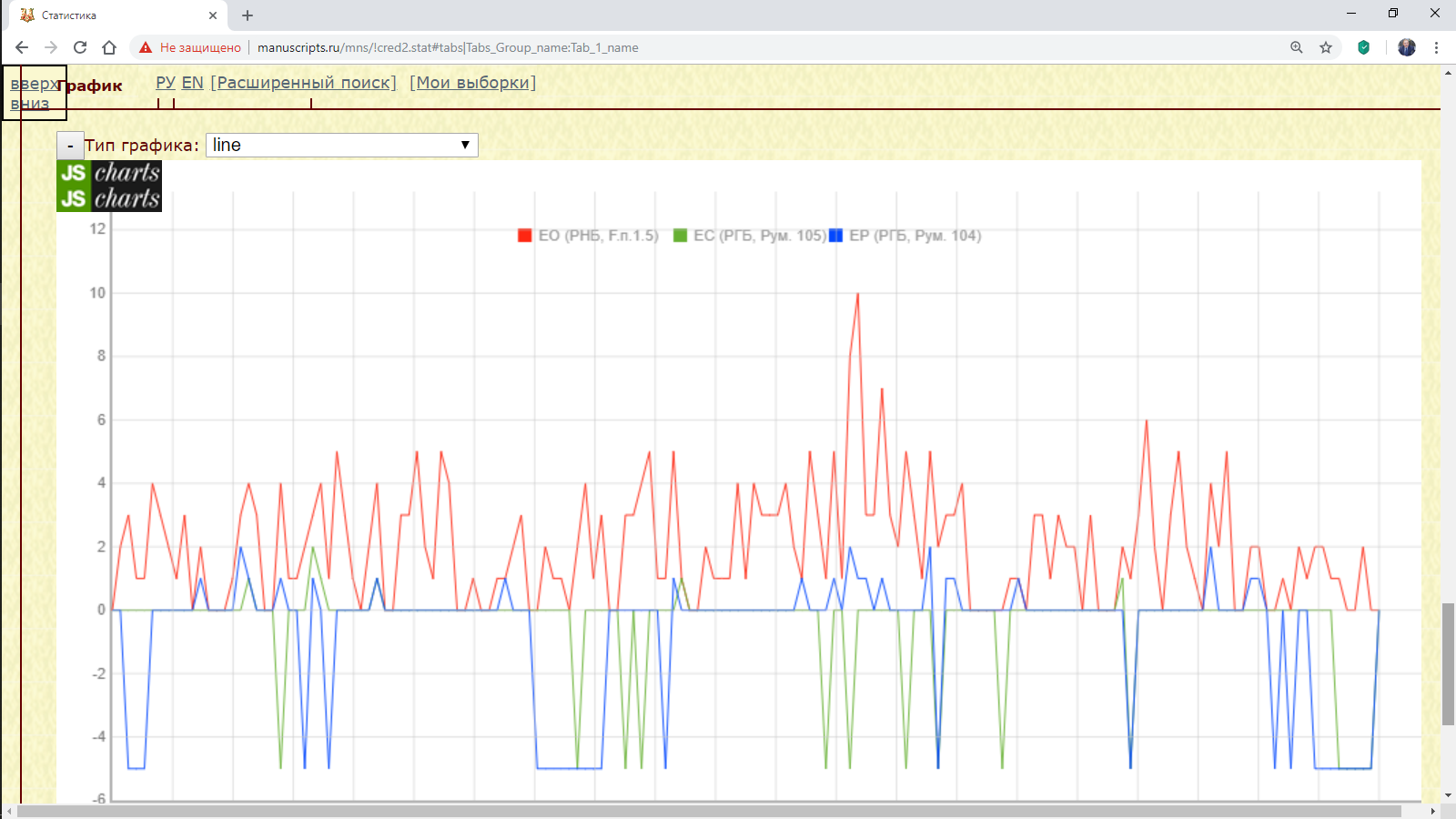
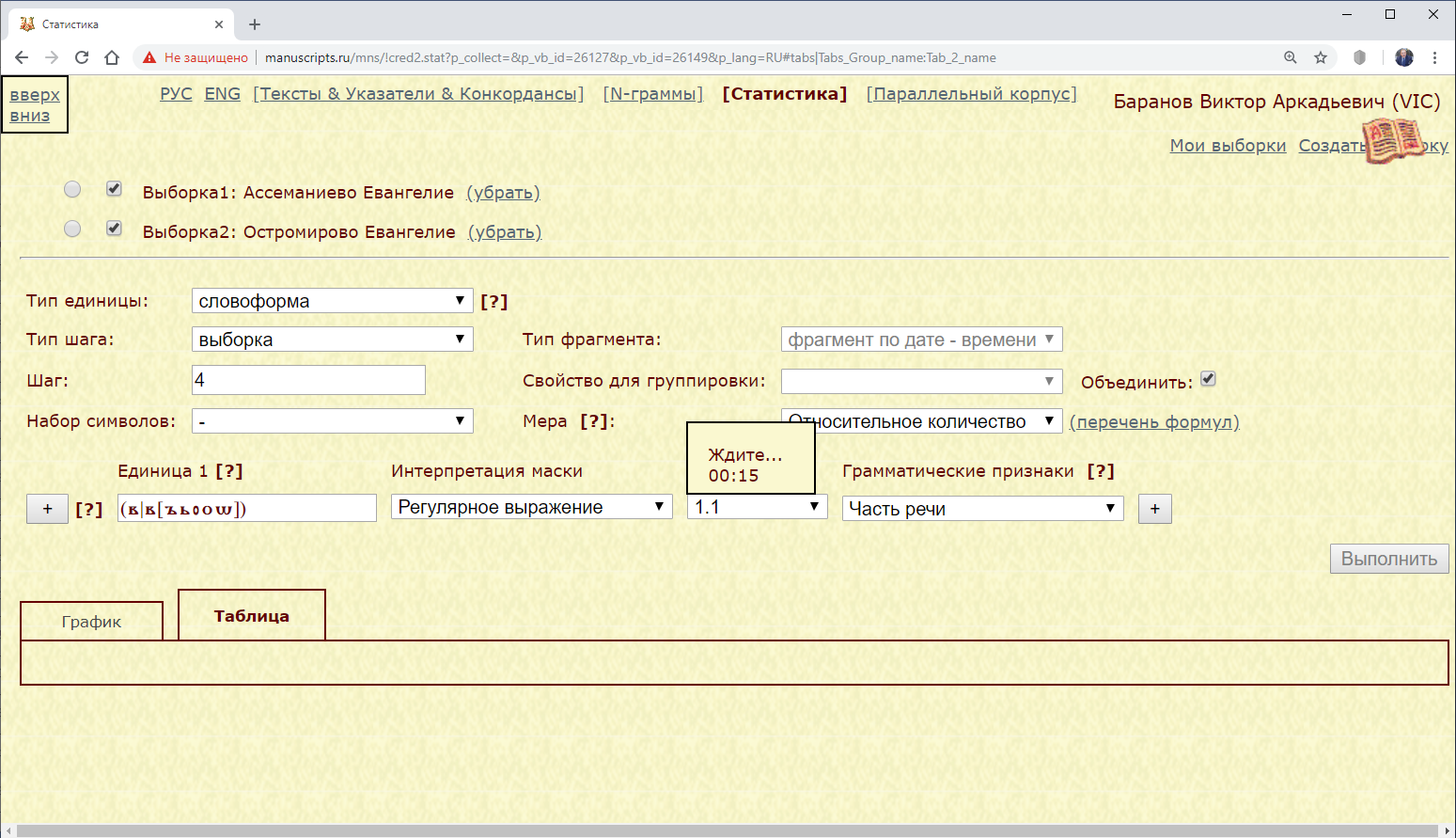
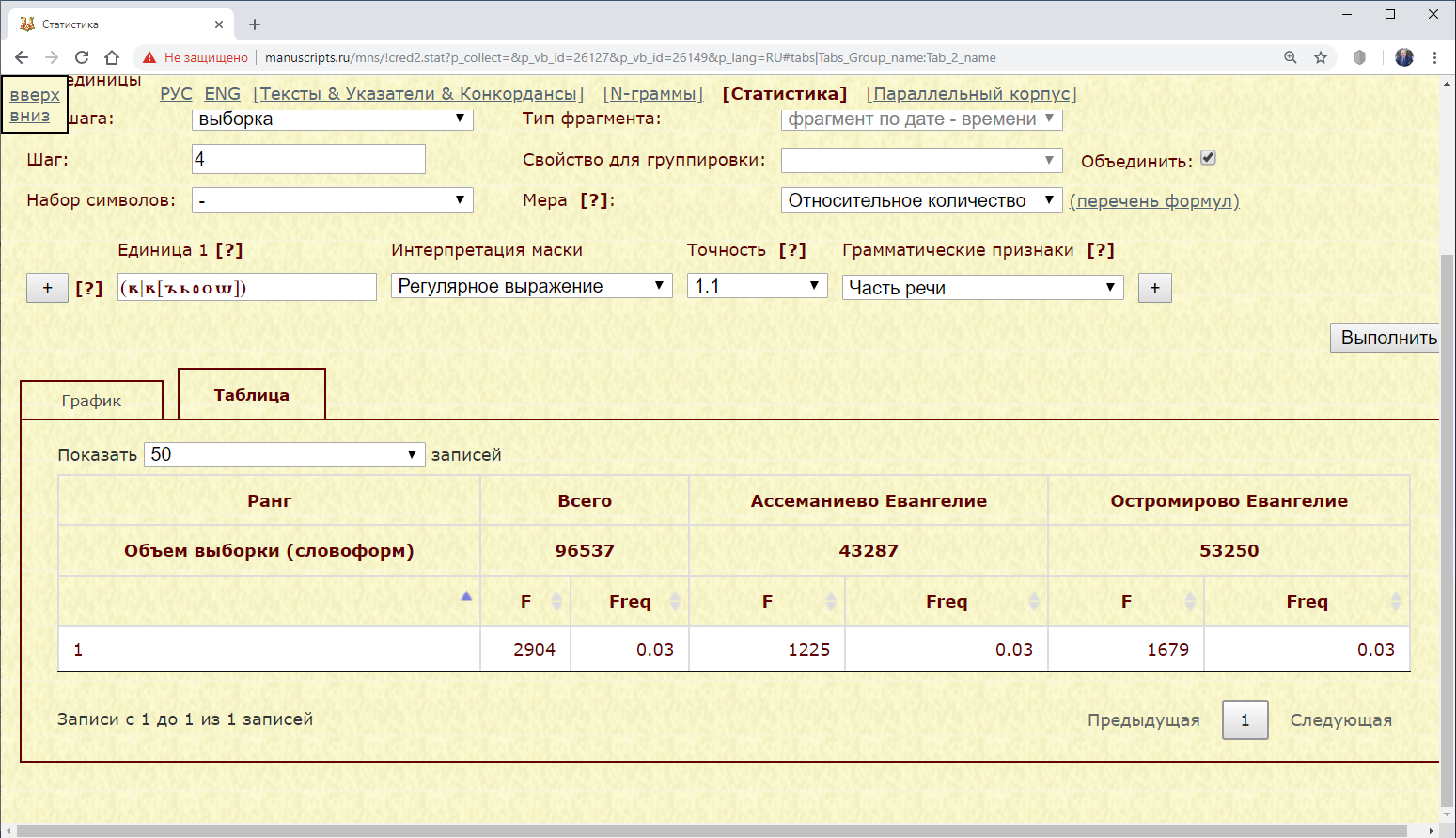
Пример 3.2.3.2. Найти абсолютное и относительное количество предлога “въ” в Ассеманиевом и Остромировом Евангелиях.
Рис. 3.2.2.3.а. Запрос для нахождения количества предлога въ в Остромировом и Архангельском Евангелиях
Использование маски на основе регулярного выражения позволяет устранить вариативность текстовых форм.
Результат:
Рис. 3.2.2.3.б. Количество предлога въ в Остромировом и Архангельском Евангелиях
Изменение значения параметра Точность позволяет выявить степень варьирования текстовых форм в каждом из подкорпусов.
Использование значения текст как единицы анализа предполагает подсчет текстов в каждой из выборок или демонстрацию сведения о них.
Для нахождения количества текстов в выборках или демонстрации сведений о них:
Примечание.
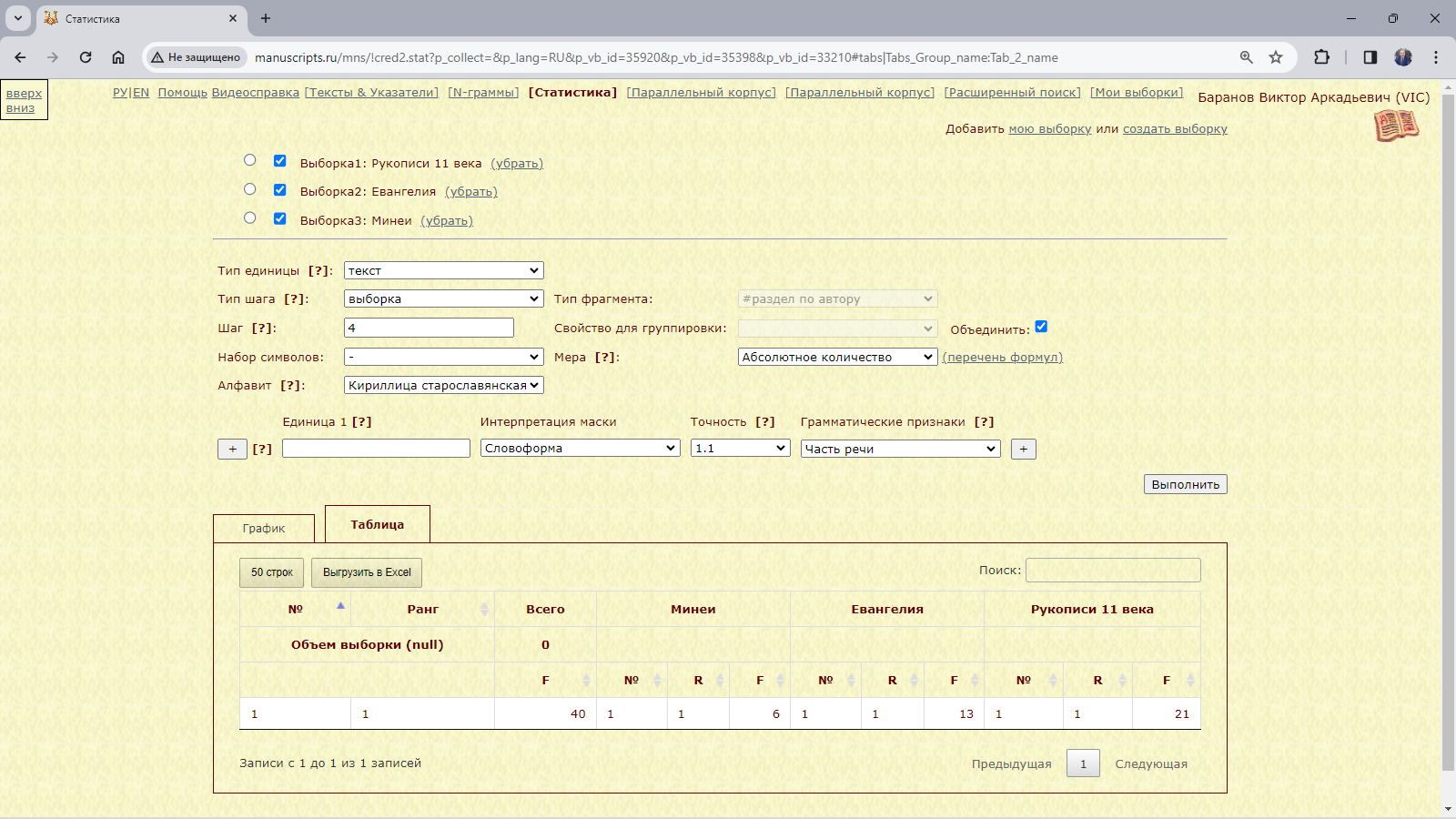
Пример 3.2.4. Найти количество текстов в каждом из подкорпусов.
Рис. 3.2.4.а. Запрос для нахождения количества текстов в выборках и результат
Результат:
Рис. 3.2.4.в. Перечни текстов в подкорпусах миней, Евангелий, коллекции XI века
Для нахождения количества лингвистических единиц в подкорпусах, сформированных на основе аналитических сведений о фрагментах, необходимо создать выборки и использовать режим работы с выборками (Тип шага - выборка).
Для нахождения количественных данных о символах, словоформах, леммах во фрагментах рукописей или текстов с учетом типов фрагментов:
Примечания.
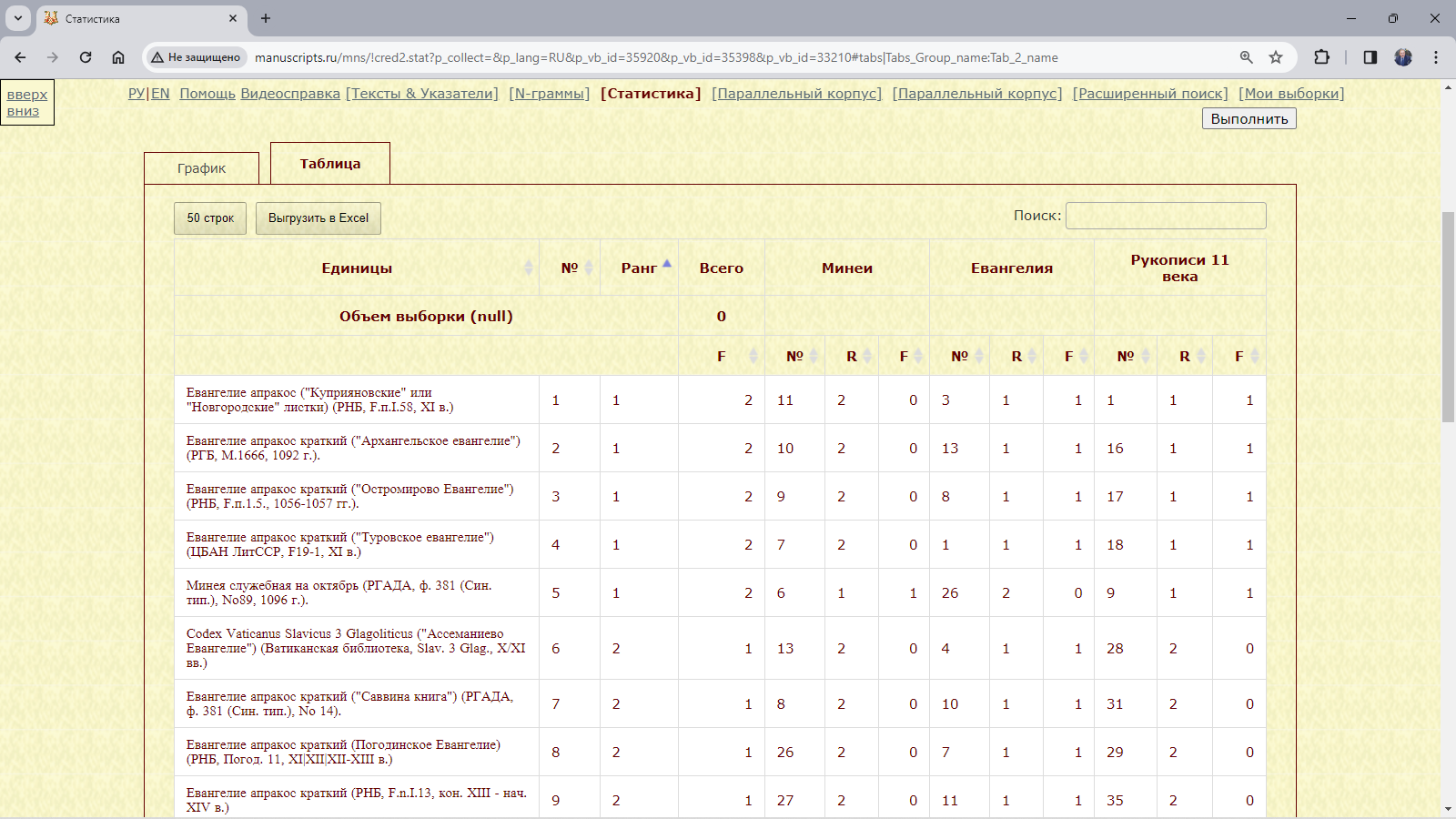
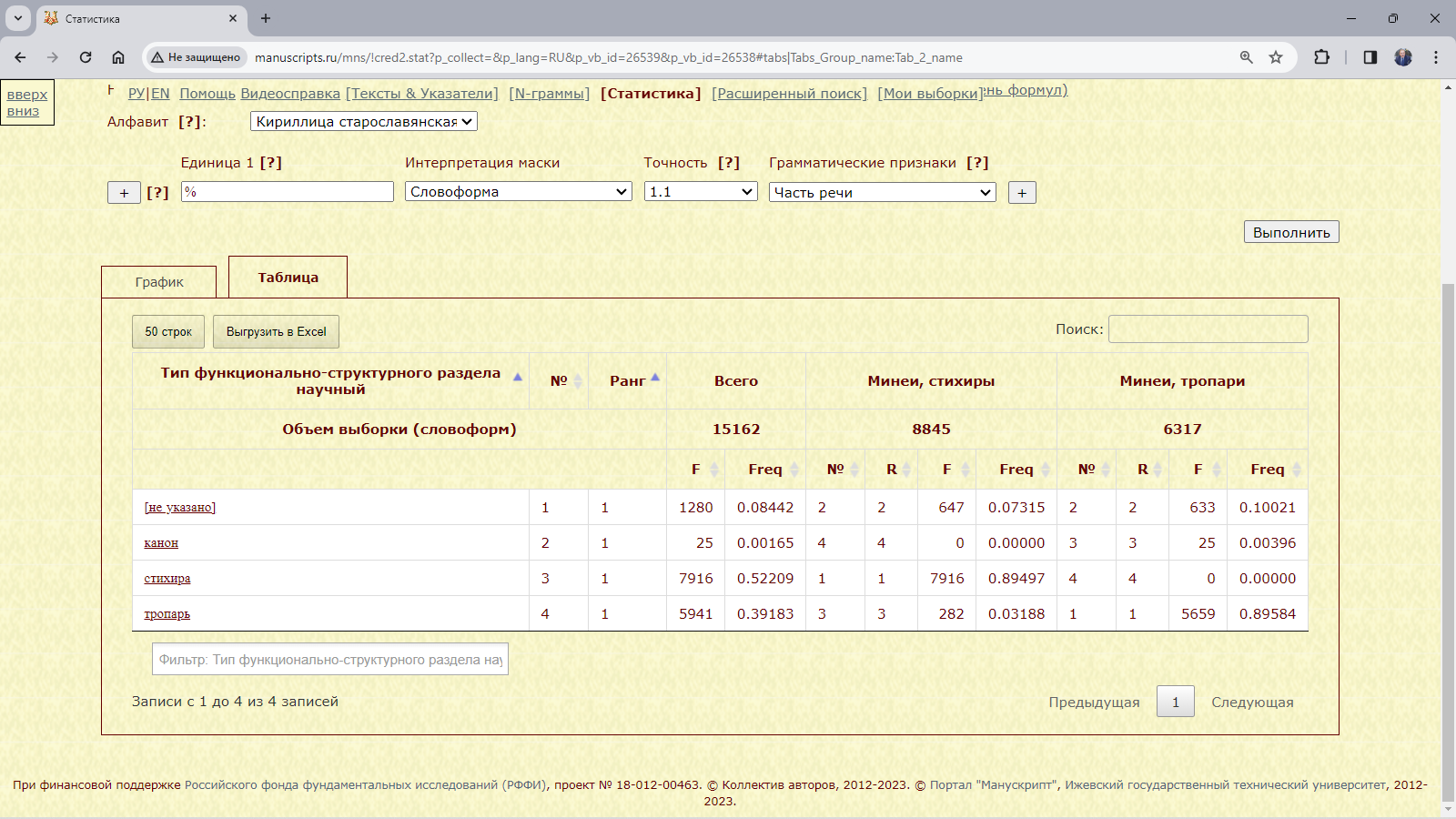
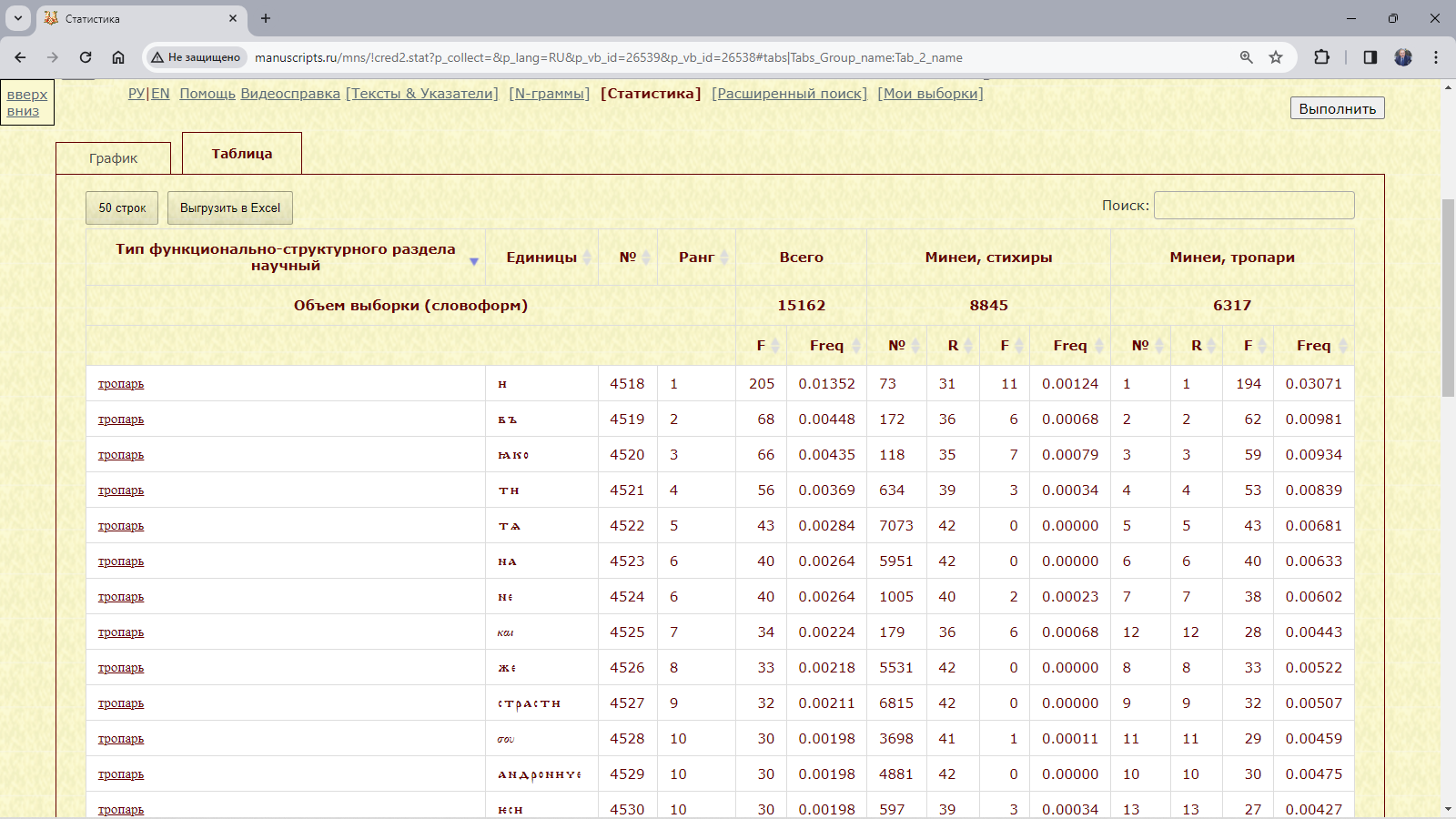
Пример 3.2.5. Найти относительное и абсолютное количество всех словоформ в тропарях и стихирах всех списков служебной минеи на май.
Рис. 3.2.5.а. Запрос для нахождения относительного и абсолютного количества всех словоформ в тропарях и стихирах списков служебной минеи на май
Результат:
Рис. 3.2.5.б. Относительное и абсолютное количество всех словоформ в тропарях и стихирах списков служебной минеи на май
Рис. 3.2.5.в. Перечень всех словоформ в тропарях и стихирах списков служебной минеи на май
Для сопоставления выборок используются следующие параметры и их значения:
Параметр Алфавит используется для поиска и вывода данных в транслитерированной форме на основе в том числе современного кирилловского алфавита, что позволяет нивелировать различия при поиске и подсчете, например, между О и Ѡ, являющимися разными буквами старославянского алфавита.
Примечание. Параметр Шаг не используется.
Использование статистических мер позволяет извлечь из подкорпуса единицы, частотность которых отклоняется от средней частотности в некотором контрольном подкорпусе. Поэтому применение статистических мер предполагает нахождение ожидаемой частотности в одном подкорпусе и наблюдаемой частотности в другом – анализируемом.
Подготовьте и загрузите несколько выборок, как это сказано в разделе 2.
Для нахождения статистических значений символов, словоформ, лемм в рукописях, текстах или фрагментах:
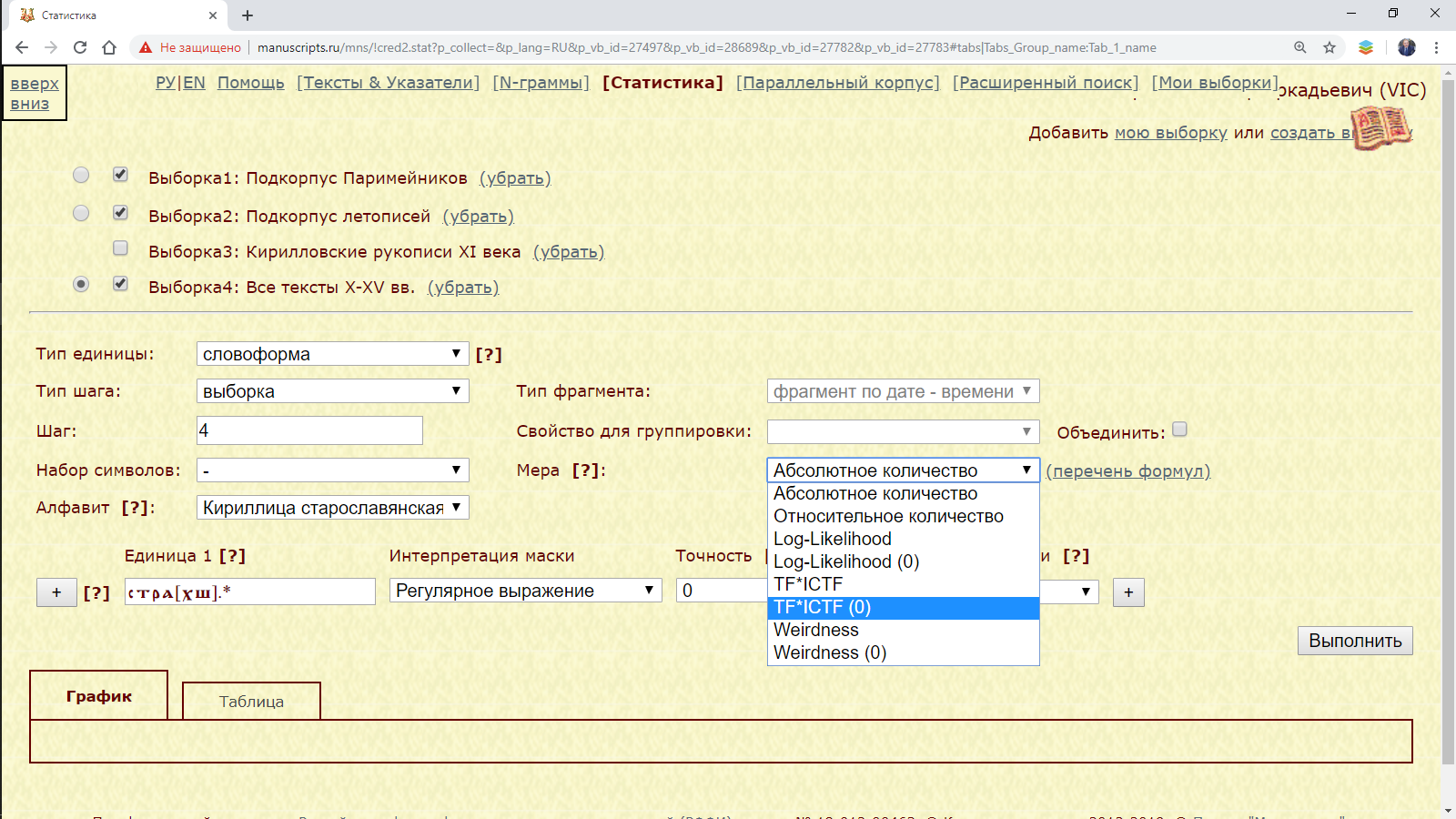
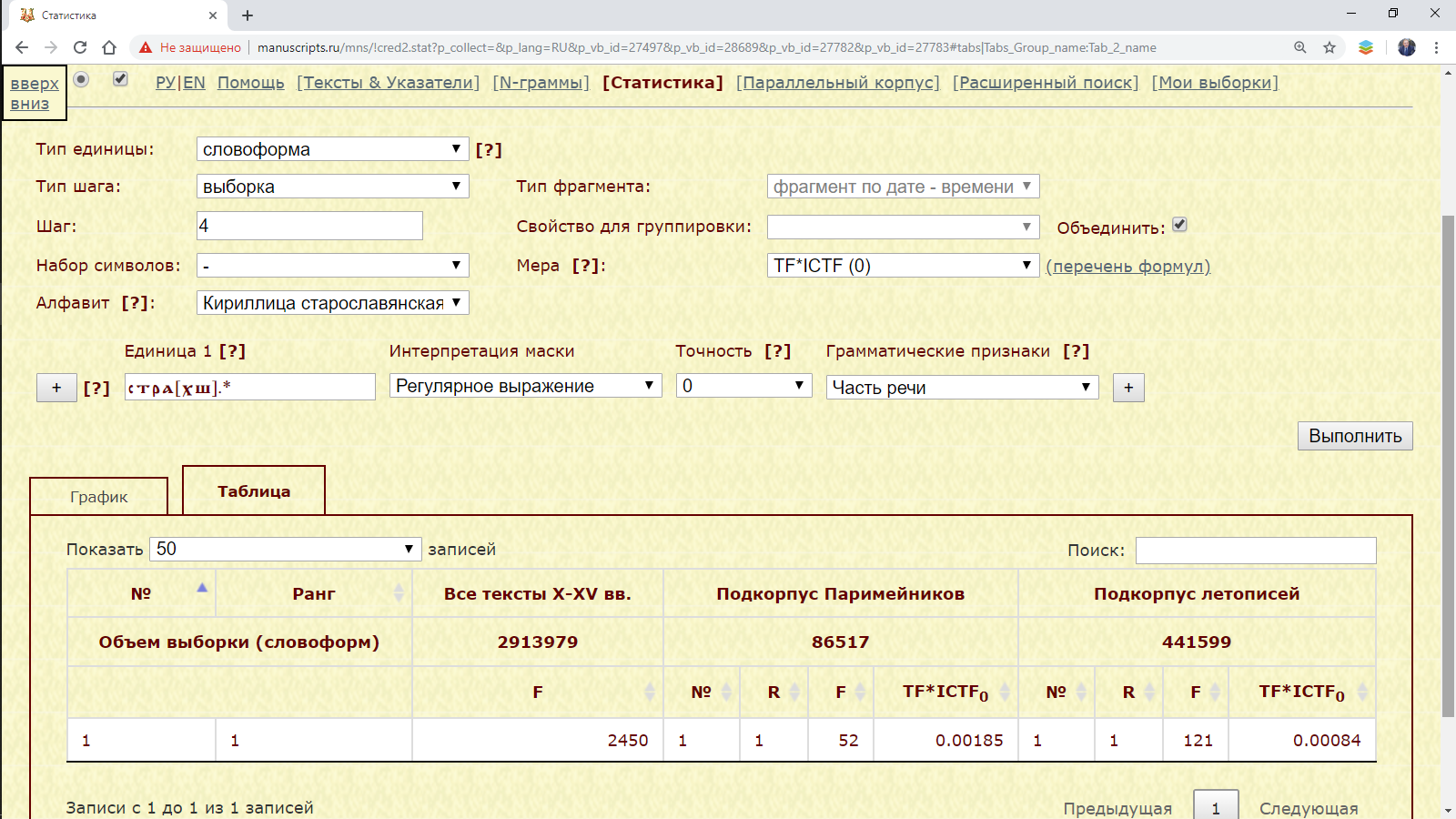
Пример 3.3.2.1. Найти слова с начальным стра(х|ш) с наибольшими значениями меры TF*ICTF в подкорпусах Паримейников и летописей (контрастный подкорпус – тексты X-XV веков).
Рис. 3.3.2.1.а. Запросная форма для поиска слов с начальными стра(х|ш) с наибольшими значениями меры TF*ICTF в подкорпусах Паримейников и летописей (контрастный подкорпус – тексты X-XV веков)
Примечания.
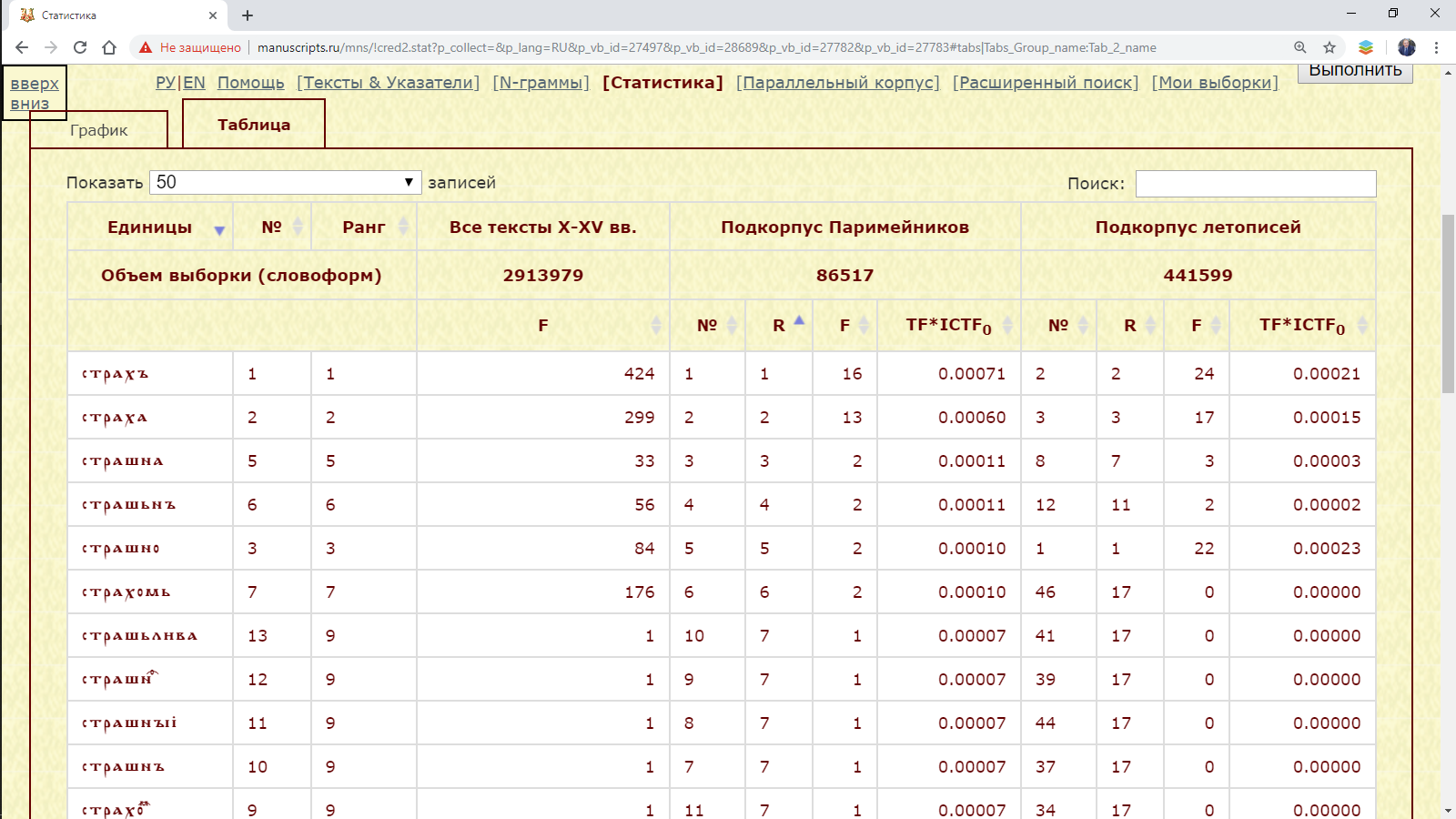
Результат. Таблица результата содержит перечень единиц, их номера по порядку, ранги, абсолютные частоты и статистические веса. Единицы отсортированы по их статистическому весу в одном из анализируемых подкорпусов.
Результат: перечень слов с начальным стра(х|ш) с наибольшим значением меры TF*ICTF в подкорпусах Паримейников и летописей в сравнении с текстами X-XV веков.
Рис. 3.3.2.1.б. Перечень слов с начальными стра(х|ш) с наибольшими значениями меры TF*ICTF в подкорпусах Паримейников и летописей (контрастный подкорпус – тексты X-XV веков)
Единицы можно отсортировать по значениям любого из столбцов, используя маркеры сортировки.
Использование параметра Объединить позволяет получить средний статистический вес словоформ, удовлетворяющих маске, в анализируемых подкорпусах.
Рис. 3.3.2.1.в. Средние значения меры TF*ICTF слов с начальными стра(х|ш) в подкорпусах Паримейников и летописей (контрастный подкорпус – тексты X-XV веков)
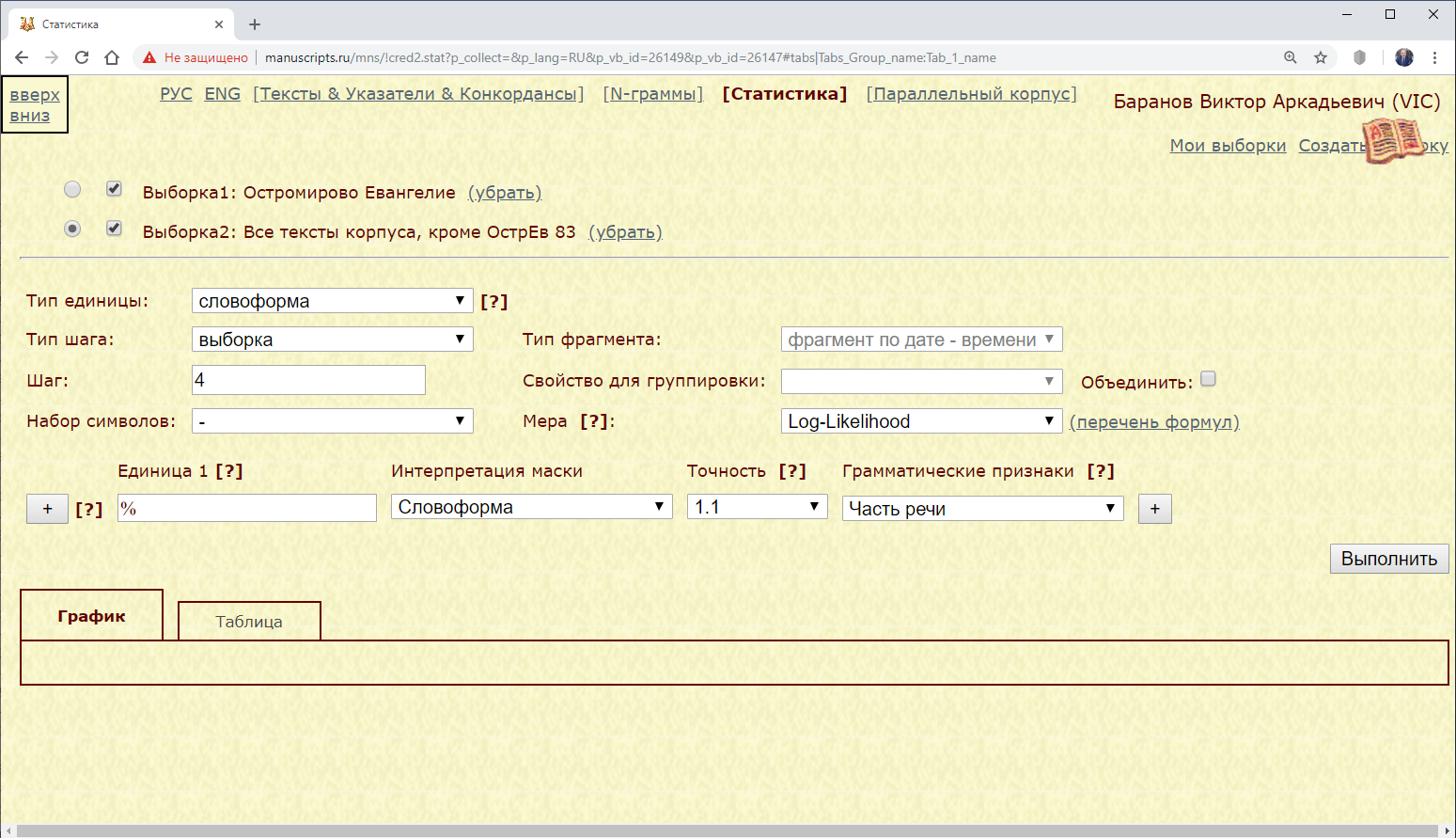
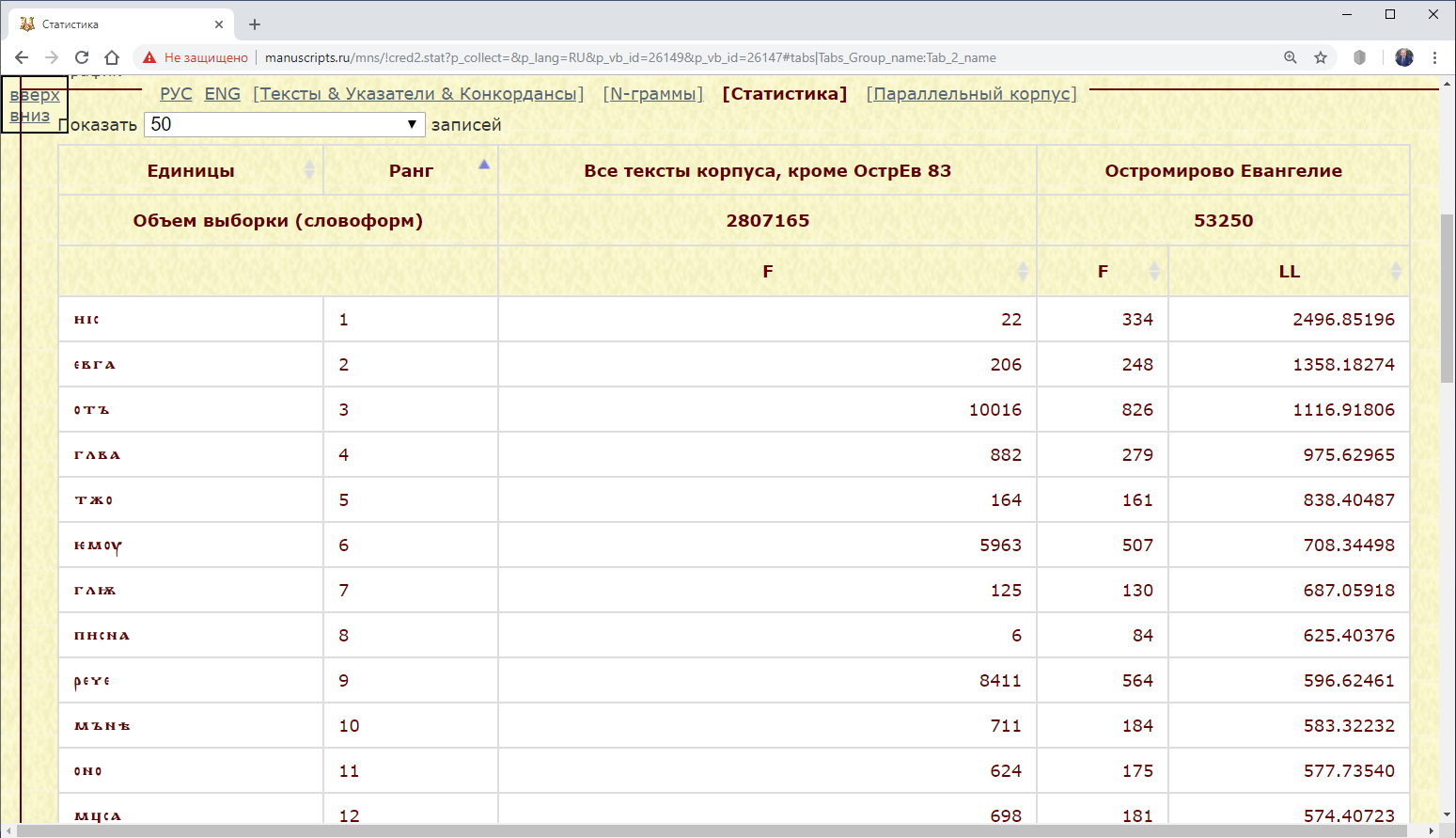
Пример 3.3.2.2. Найти статистические значения (мера Log-Likelihood) всех словоформ Остромирова Евангелия (контрастный подкорпус – все тексты корпуса).
Рис. 3.3.2.2.а. Запрос для поиска статистических значений (мера Log-Likelihood) всех словоформ Остромирова Евангелия (контрастный подкорпус – все тексты корпуса)
Результат:
Рис. 3.3.2.2.б. Статистические значения (мера Log-Likelihood) всех словоформ Остромирова Евангелия (контрастный подкорпус – все тексты корпуса)
Наличие метаданных текстов позволяет сопоставить количество символов или лингвистических единиц в группах текстов (рукописей), различающихся метаданными - жанром или временем создания.
Подготовьте выборку, содержащую несколько текстов (рукописей), и загрузите ее.
Для сопоставления количества символов, словоформ, лемм в рукописях или текстах:
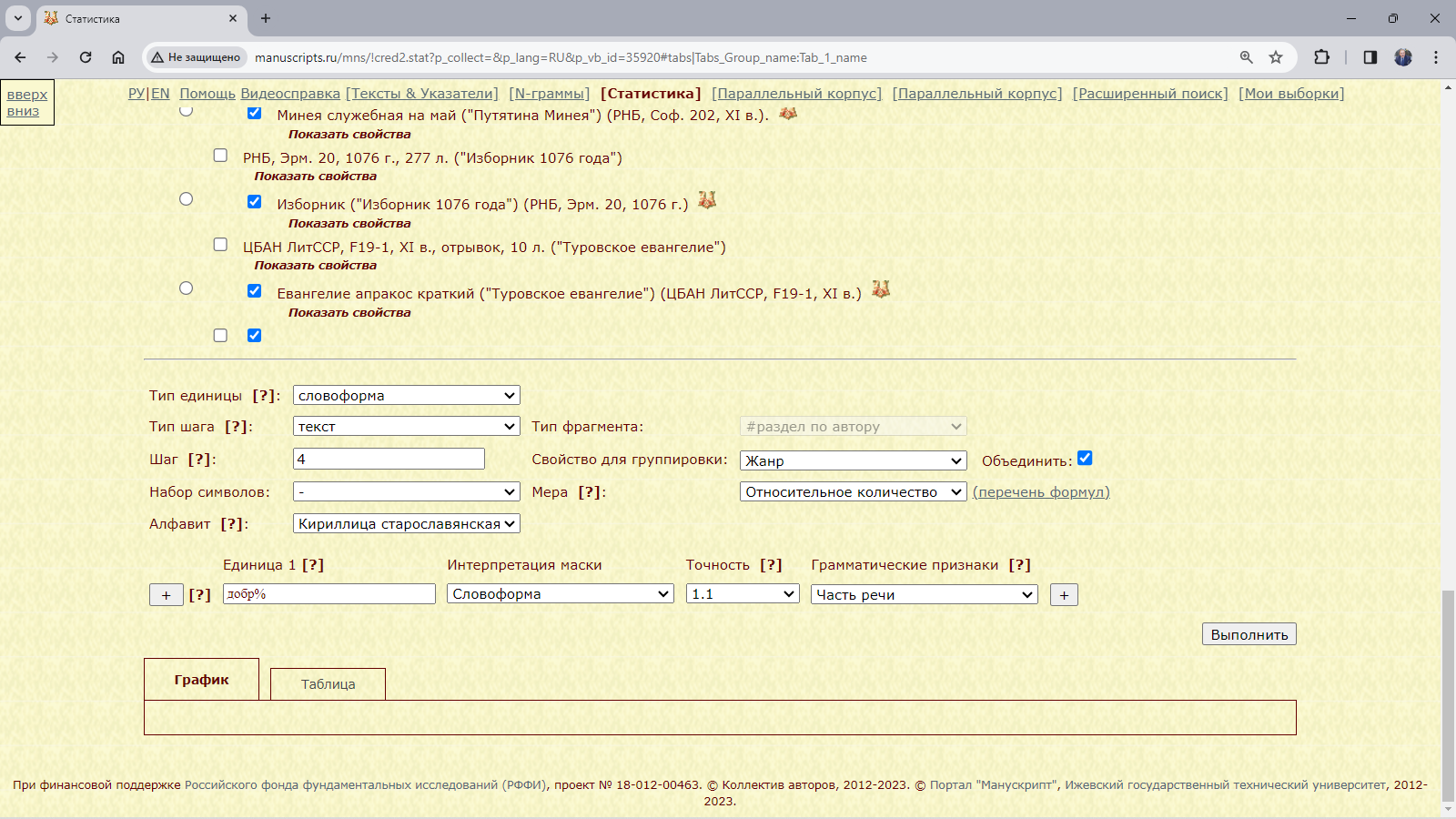
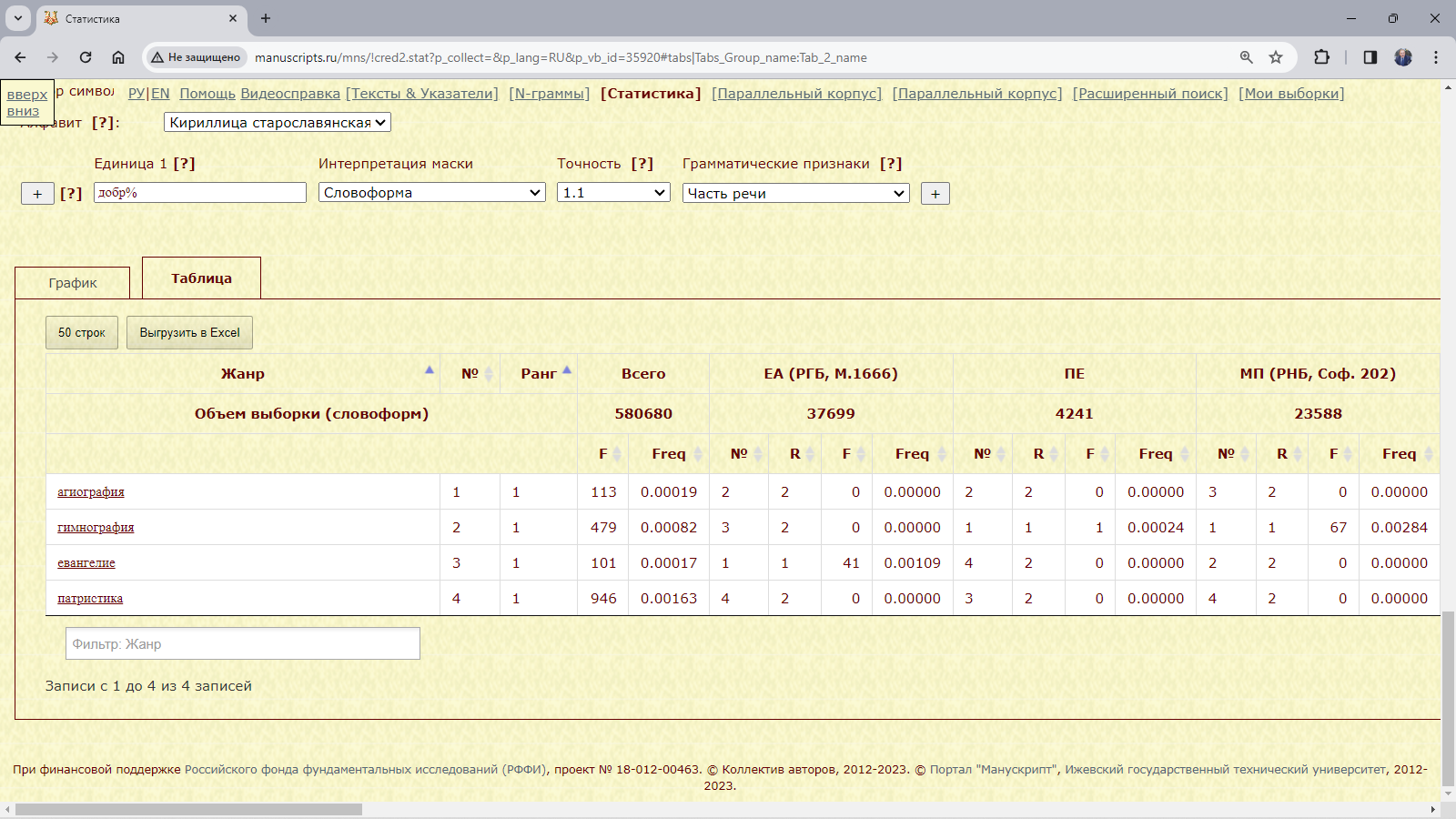
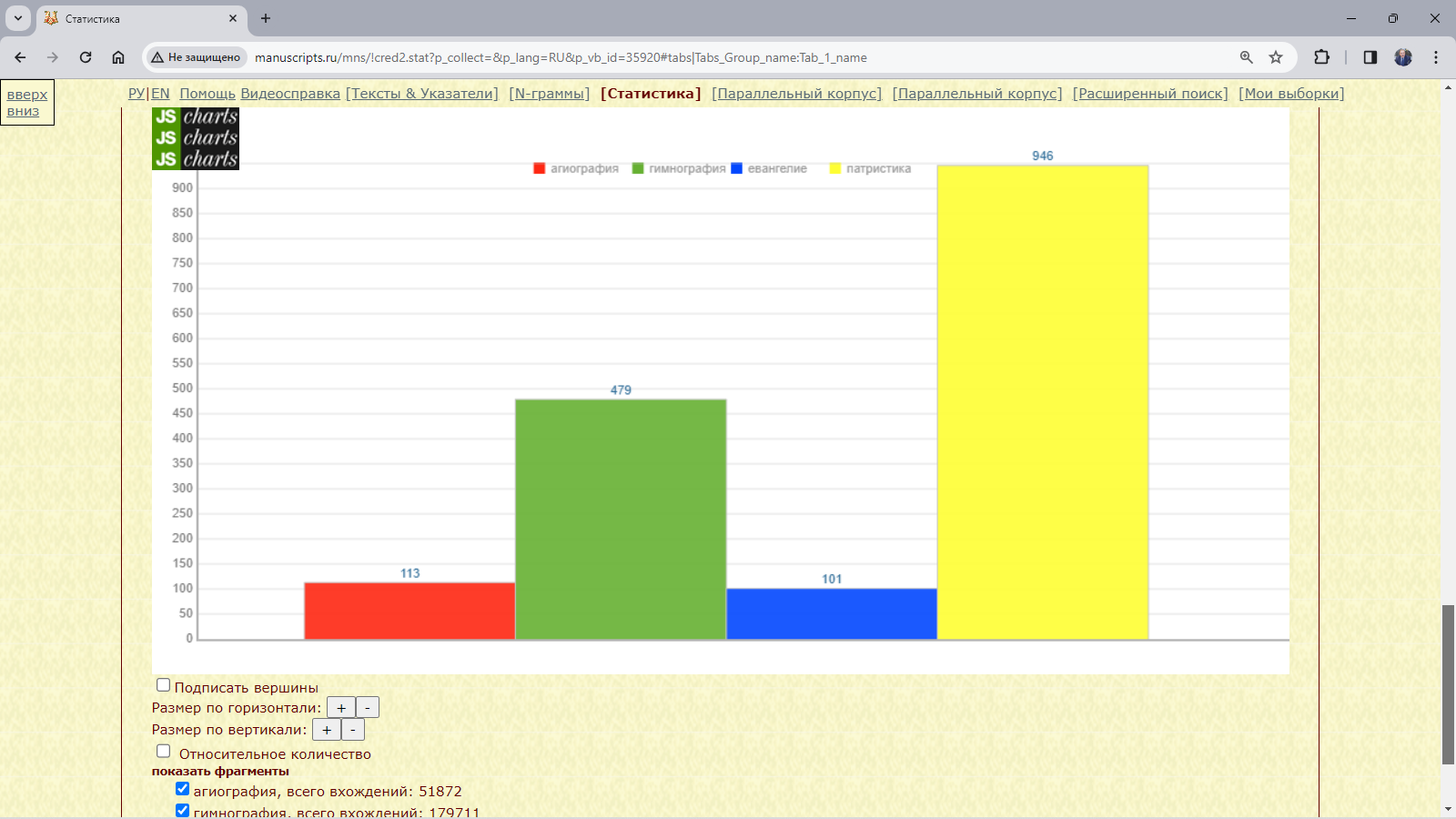
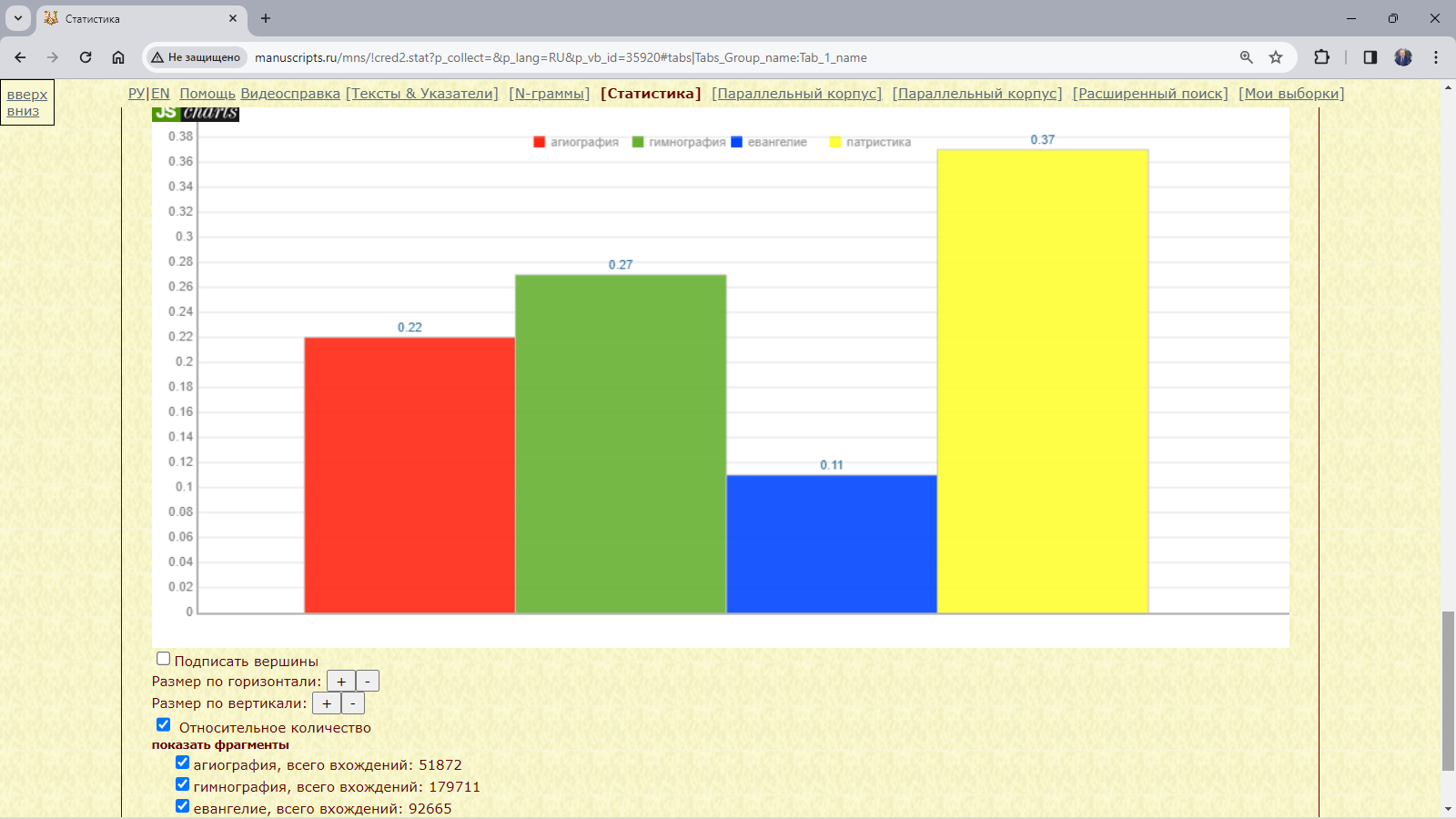
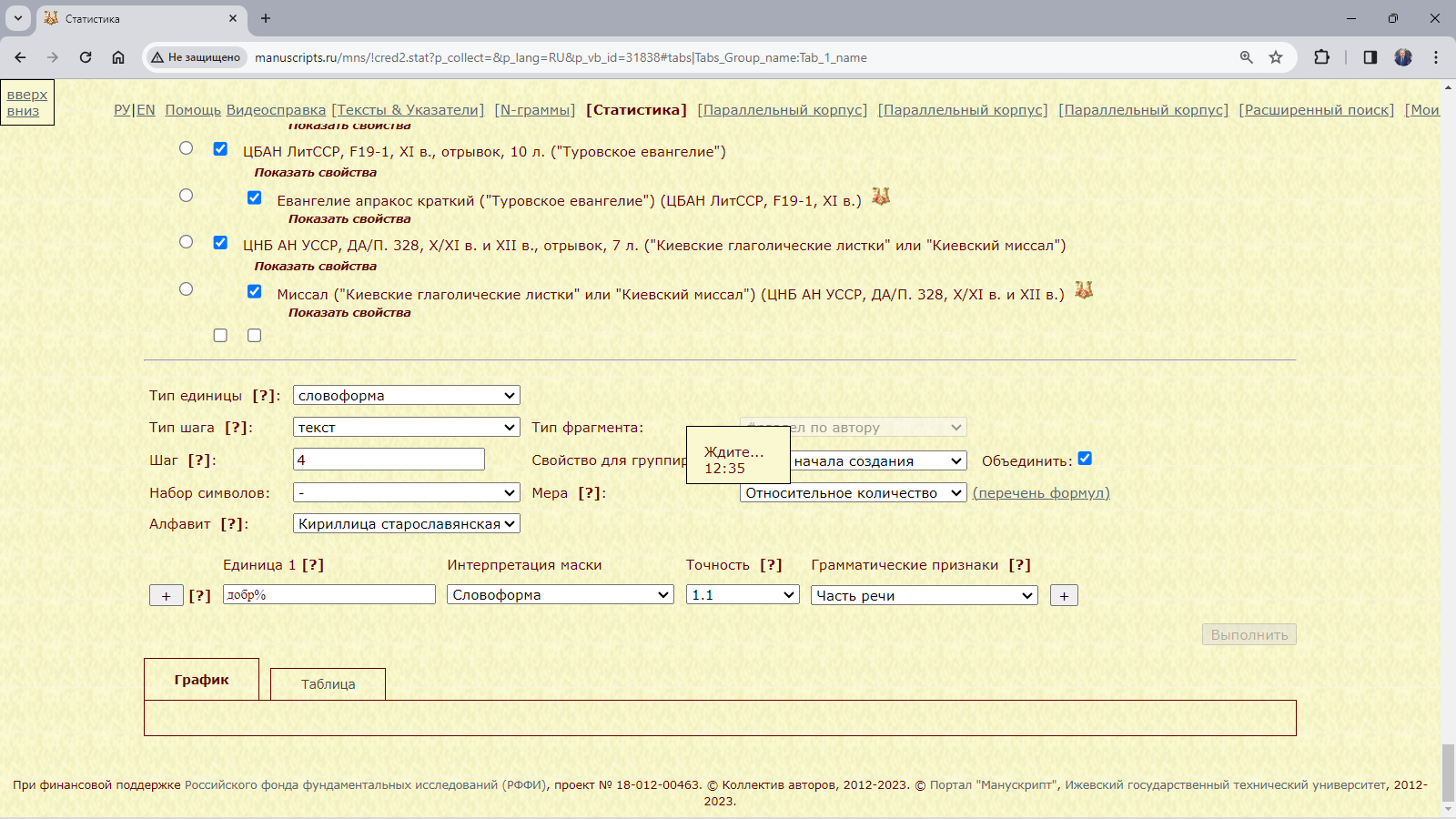
Пример 3.4.2.1. Найти относительное количество слов с начальным добр- в рукописях XI века, различающихся жанром.
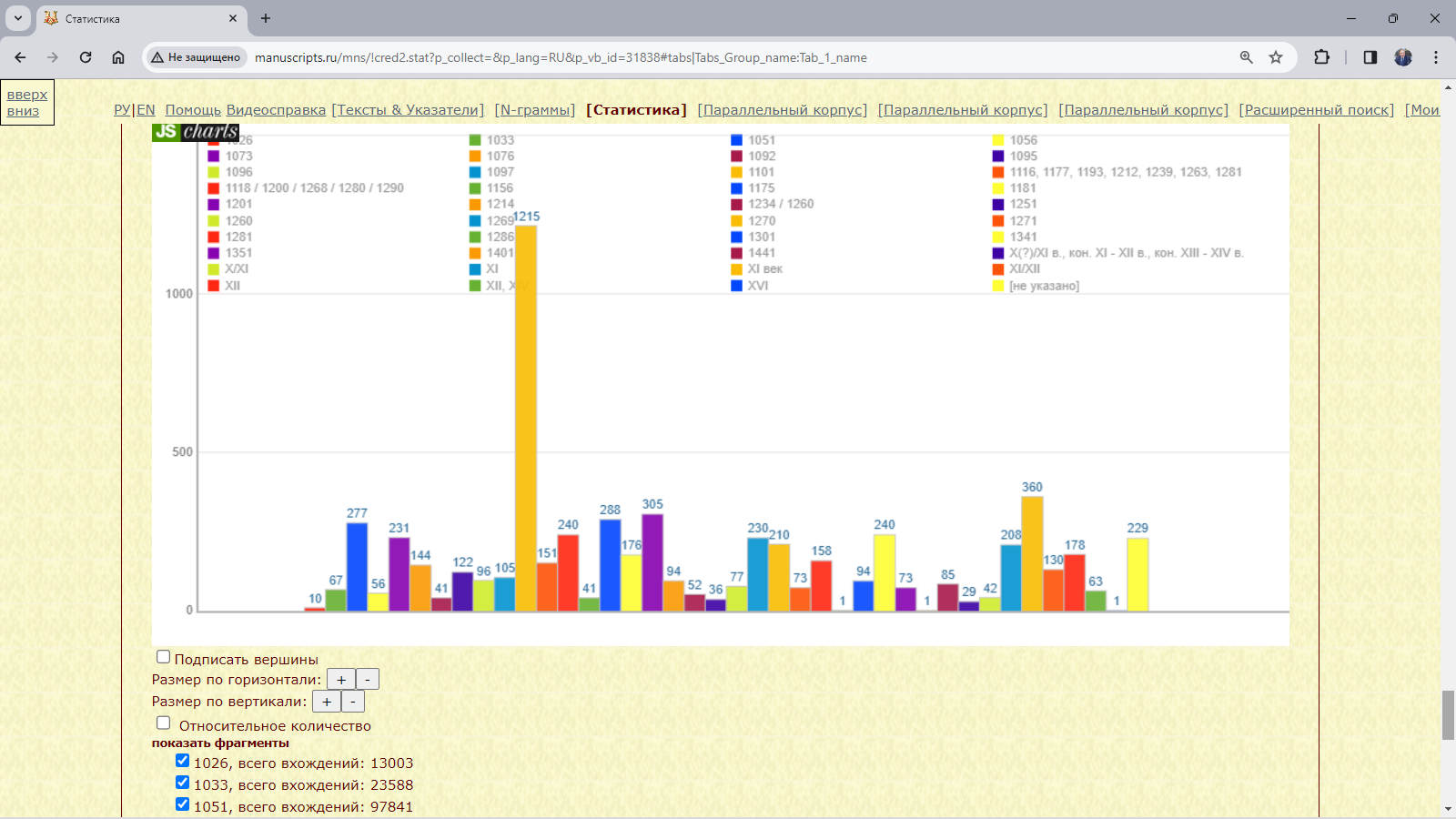
Рис. 3.4.2.1.а. Запросная форма для поиска слов с начальными добр- в подкорпусе рукописей XI века, различающихся жанром
Рис. 3.4.2.1.б. Результат запроса для поиска слов с начальными добр- в подкорпусе рукописей XI века, различающихся жанром (таблица): абсолютное и относительное количество
Рис. 3.4.2.1.в. Результат запроса для поиска слов с начальными добр- в подкорпусе рукописей XI века, различающихся жанром (диаграмма): абсолютное количество
Рис. 3.4.2.1.г. Результат запроса для поиска слов с начальными добр- в подкорпусе рукописей XI века, различающихся жанром (диаграмма): относительное количество
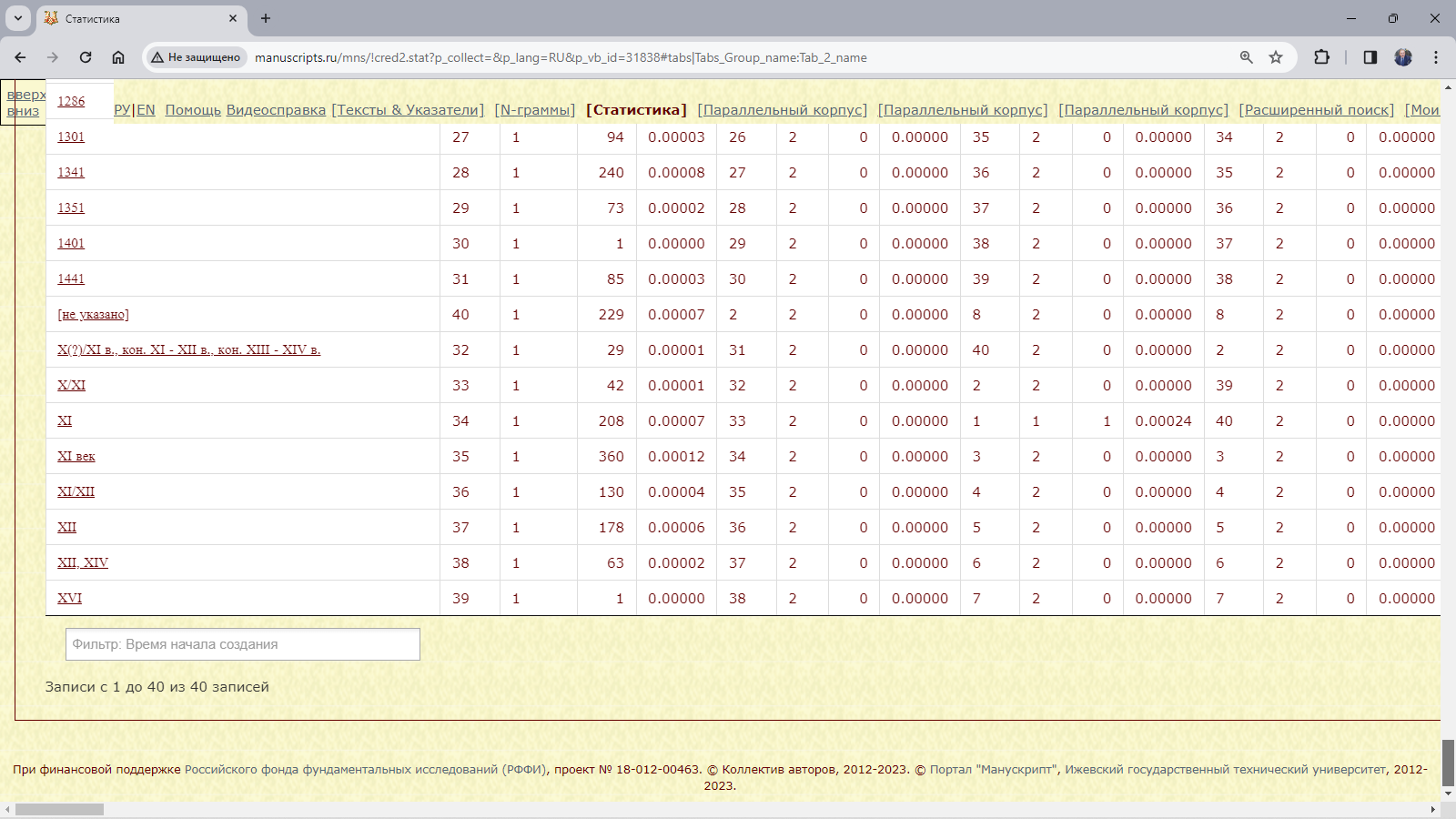
Пример 3.4.2.2. Найти слова с начальным добр- в рукописях корпуса, различающихся временем создания.
Рис. 3.4.2.2.а. Запросная форма для поиска слов с начальными добр- в рукописях корпуса, различающихся временем создания
Рис. 3.4.2.2.б. Результат запроса для поиска слов с начальными добр- в рукописях корпуса, различающихся временем создания (таблица)
Рис. 3.4.2.2.в. Результат запроса для поиска слов с начальными добр- в рукописях корпуса, различающихся временем создания (диаграмма)
Единицами подсчета (анализа) могут быть символы, словоформы, леммы, тексты.
Для анализа отдельных символов, текстовых форм, начальных форм, текстов выберите соответствующее значение параметра и введите в поле “Единица” маску единицы.
Подсчет единиц анализа может быть осуществлен как во всем подкорпусе, так и в его частях. Части подкорпуса, в которых осуществляется подсчет анализируемых единиц, называются шагами.
При анализе одной выборки выберите значения – знак, словоформа, страница, лист, фрагмент, текст.
При анализе нескольких выборок выберите значения – фрагмент, выборка.
Примечание. Для всех значений, кроме “выборка”, должно быть указано значение свойства “Группировка”.
Группировка единиц подкорпуса устанавливается с помощью выбора одной из их характеристик. Так, тексты могут быть сгруппированы по жанру, по автору, по теме, рукописи – по дате создания, по количеству листов, фрагменты – по типу, листы – по порядку следования и т. п.
По умолчанию группировка единиц следующая:
При необходимости иной группировки укажите иное значение единицы.
Выбор текста, рукописи, фрагмента в качестве единицы шага требует обязательного выбора группировки.
Подсчет анализируемых единиц может осуществляться как в каждой отдельной части подкорпуса, так и в группах (шагах) из нескольких частей. Количество частей, входящих в группу, называется длиной шага.
По умолчанию длина шага равна одной части.
При необходимости укажите иную длину шага.
Примечание. Для фрагментов, текстов и выборок длина шага не устанавливается.
Объединение позволяет суммировать количество лингвистических единиц в частях подкорпуса, а в случае использования неточной маски – суммировать данные о разных лингвистических единицах, соответствующих маске поиска.
Значение Кириллица современная параметра “Алфавит” используется для поиска и вывода данных в транслитерированной форме на основе современного кирилловского алфавита, что позволяет нивелировать различия при поиске и подсчете, например, между О и Ѡ, являющимися разными буквами старославянского алфавита.
При необходимости перечень единиц в форме вывода может быть визуализирован латинскими буквами.
Для глаголических текстов могут быть использованы различные варианты транслитерации на основе старославянской кириллица и латиницы.
Для получения сведений об абсолютном или относительном количестве анализируемых лингвистических единиц или о их статистических значениях выберите необходимое значение, например, “Относительное количество” или Weirdness.
Примечание. Статистические параметры используются только в режиме сопоставления анализируемого подкорпуса с контрастным подкорпусом.
Для анализа всех символов, словоформ, лемм подкорпуса(ов) в поле “Единица” введите символ процента – %.
Для поиска конкретных единиц с помощью виртуальной клавиатуры введите в поле “Единица” ее буквенную маску или ее части, например, въ или въ%.
Примечания.
Для использования расширенного набора буквенных символов, а также небуквенных знаков для ввода маски выберите нужный диапазон.
Примечание. По умолчанию виртуальная клавиатура содержит основные буквенные символы старославянского алфавита.
Для анализа сочетаний лингвистических или иных единиц откройте два или более полей “Единица”, используя символ “+” слева от поля.
С помощью параметра “Расстояние” задайте контактное или дистантное расположение единицы. При значении “от 0 до 0” будут найдены сочетания с контактным расположением компонентов, при “от 1 до 1” – с одной словоформой между компонентами, при “от 0 до 1” – все сочетания с контактным расположением компонентов или с одной словоформой между компонентами.
Если в поле “Единица” маска имеет символы % или _, то результатом поиска является перечень из нескольких единиц. Для получения суммированного результата используйте параметр “Объединить”.
Маска может быть использована для поиска различных лингвистических единиц:
Маска может быть задана с использованием регулярных выражений. В таком случае выберите значение “Регулярное выражение”.
Используйте параметр “Точность” для точного или неточного поиска. С помощью значений параметра указывается степень совпадения маски с текстовыми формами.
Значения 0 и 0.1 соответствуют максимально точному совпадению.
Примечания.
Для поиска и демонстрации лингвистических единиц с определенными грамматическими значениями с помощью выпадающего меню выберите свойство, с помощью плюса справа откройте значения свойства и выберите значение, например для “Часть речи” – “Существительное”.
Примечания.
При анализе лемм предоставляется возможность использовать результаты автоматического снятия омонимии, которое обеспечивает приведение текстовой формы лишь к одной начальной форме. Для этого при поиске и демонстрации лемм в параметре “Словарь” выберите “ГСДРЯ”, включите значение “Снимать омонимию”.
Примечания.
После выполнения запроса становятся доступны несколько дополнительных возможностей – сортировка и уточнение выборки, а также поиск в выборке.
Для изменения сортировки выборки используются стрелки △ ▽ в правой части заголовка нужного столбца.
Для дополнительной сортировки перечня единиц используются стрелки △ ▽ в заголовке столбца форм при нажатой клавише Shift.
Для поиска единицы выборки в правом верхнем углу таблицы с результатами введите маску.
Данные выборки могут быть уточнены с помощью поля “Фильтр”, которое позволяет выбрать одну или несколько единиц (рукописей, текстов, фрагментов), включенных в подкорпус.
Для получения сведений о лингвистических единицах некоторой части анализируемого подкорпуса выберите одну или несколько единиц.
Примечание. Используйте клавишу Ctrl для выбора нескольких единиц.
При формировании запроса могут быть использованы различные сочетания параметров.
Используемые в запросе параметры и их значения определяются пользователем и зависят от решаемой задачи.
Примечания.
Параметры запросной формы имеют контекстные подсказки.